ilert stellt mithilfe unserer vorgefertigten Integrationen oder per E-Mail eine nahtlose Verbindung zu Ihren Tools her. Ilert lässt sich in Überwachungs-, Ticketing-, Chat- und Kollaborationstools integrieren.
So erreichen führende Unternehmen mit ilert eine Uptime von 99,9 %
Unternehmen weltweit vertrauen auf ilert, um ihr Incident-Management zu optimieren, die Zuverlässigkeit zu steigern und Ausfallzeiten zu minimieren. Lesen Sie, was unsere Kunden über ihre Erfahrungen mit unserer Plattform sagen.
KI einfach an ein Produkt anzuhängen, ist schwieriger als gedacht
Es ist 2:47 Uhr morgens. Eine P1-Alarmierung wird ausgelöst. Der dienstbereite Techniker öffnet ilert, sieht, dass die KI bereits eine Analyse durchgeführt hat, und erhält drei Remediation-Optionen. Aber wie geht es dann weiter? Das hat uns ganz besonders beschäftigt.
Die meisten KI-Tools präsentieren dem Techniker in diesem Moment eine nummerierte Liste in einem Chatfenster und warten. Der Techniker liest, trifft seine Auswahl, tippt eine Antwort ein, und der Agent setzt die Arbeit fort. Das alles dauert – wenn Eile geboten ist - nur einige Sekunden, führt aber genau im falschen Moment zu Unklarheiten, erneutem Lesen und kognitiver Belastung.
Wir entwickelten einen SRE-Agenten, d.h. einen direkt in unsere Incident Response-Plattform integrierten KI-Agenten, der alles übernimmt – von der Root Cause Analysis (RCA) und Triage bis hin zu On-Call-Anfragen und der Objekterstellung. Da wir Agenten zu einem zentralen Bestandteil unserer Lösung gemacht haben, wurden wir immer wieder mit der Frage konfrontiert: Welches ist die richtige Schnittstelle für einen Menschen, der während eines aktiven Incidents eine KI-Entscheidung genehmigen soll?
Chat ist die naheliegende Lösung. Aber es ist nicht immer die richtige.
Läuft der Agent als Sidecar? Als Overlay? Gibt es einen speziellen Ort, um mit ihm zu kommunizieren? Ist der Chat die einzige Schnittstelle?
Für Chat spricht vor allem eines: Der Agent kann überall dort sein, wo der Nutzer ist: Slack, WhatsApp, Teams. Wann immer er Input benötigt, erreicht er den Menschen über seinen bevorzugten Kanal.
Aber der Chat hat auch Nachteile: Oft ist der Eingabeaufwand immer noch zu hoch. Nutzer wissen nicht immer, was sie eingeben sollen oder wo sie anfangen sollen. Und wenn man die Interaktion in einen Chat-Kanal verlagert, ist man auf das beschränkt, was dieser Kanal unterstützt: in der Regel nur Text.
Unsere Herangehensweise ist:
Die beste agentengestützte UX fühlt sich nicht wie ein Chatbot an, sondern vielmehr so, als wäre das Produkt intelligenter geworden. ActionOption Cards sind die Realisierung dieses Ansatzes, und sie beginnen damit, ein ganz bestimmtes Problem zu lösen.
Das Problem mit textbasierten Optionslisten
Zurück zu 2:47 Uhr morgens. Die KI hat den schwierigen Teil bereits erledigt: Sie hat Meldungen aus Datadog und GitHub miteinander verknüpft, ein fehlerhaftes Deployment identifiziert und die Remediation-Optionen auf drei eingegrenzt. Diese Arbeit ist wichtig. Was als Nächstes passiert, kann sie zunichte machen.
Die meisten KI-Tools präsentieren dem Engineer eine nummerierte Liste in einem Chat-Fenster und warten. Das zwingt ihn dazu, zu lesen, sich für eine Option zu entscheiden und eine Bestätigung einzutippen – ein Reibungspunkt genau im falschen Moment und Quelle von Unklarheiten, die der Agent dann klären muss. Das Muster sieht so aus:
Goal: Implement JWT middleware for the HTTP service.
1. Deployment des Zahlungsgateways hochskalieren
2. Betroffene Pods neu starten
3. Rollback auf die vorherige Version
Dies zwingt den Nutzer, die Option zu lesen, sie gedanklich auszuwählen und eine Folge-Nachricht einzugeben, um seine Absicht zu bestätigen. Das ist unnötiger Aufwand genau im falschen Moment. Es führt auch zu Unklarheiten: Meinte der Nutzer genau Option 1 oder eine Variante davon?
Die Schnittstelle sollte entscheidungsorientiert sein, nicht nur dialogorientiert. Während eines aktiven Incidents arbeiten Engineers unter kognitiver Belastung. Jede Sekunde, die mit erneuten Lesen, Analysieren oder Eintippen verbracht wird, ist eine Sekunde, in der der Incident andauert.
Was sind A2UI (Agent-to-User Interface) ActionOption-Cards?
Wir nutzen das A2UI-Framework, um interaktive UI-Elemente dynamisch innerhalb des Agenten-Konversations-Threads darzustellen – Komponenten, die der Agent spontan generiert, keine statischen Bildschirme. Eine ActionOption-Card ist die primäre Ausdrucksform: Sie ist das, was der Agent anstelle einer nummerierten Textliste anzeigt, wann immer eine Aktion durch den Nutzer erforderlich ist.
Jede Card steht für eine einzelne, eigenständige Handlungsoption und besteht aus:
Titel: Eine kurze, eindeutige Bezeichnung für die Aktion, z. B. „Option 1: Zahlungsgateway skalieren“.
Beschreibung: Eine Erläuterung der Funktion der Aktion und der damit verbundenen Vor- und Nachteile, damit Engineers auf einen Blick eine fundierte Entscheidung treffen können.
Tag-Badge (optional): Eine farbcodierte Kennzeichnung: Empfohlen (grün), Sofort (gelb), Schnell (blau) oder Am besten (grün). Wird nur angezeigt, wenn sie eine Option sinnvoll unterscheidet.
Aktionsschaltfläche: Eine anklickbare Schaltfläche mit einem kurzen Aktionsverb und einem optionalen Symbol. Ein Klick genügt, um fortzufahren.
Ein einfaches Beispiel: Der Agent schlägt drei Optionen vor. Anstatt „1“, „2“ oder „3“ einzugeben, klicken Sie auf eine Schaltfläche. Dieses Muster lässt sich auf komplexere Szenarien übertragen: Auswahlmenüs, Schieberegler, umfangreiche Tabellen.
Technische Architektur: So werden Cards generiert und dargestellt
Diese drei Dinge sorgen dafür, dass es funktioniert: das LLM, einige wenige Tools und das Frontend.
Schritt 1: Tool-Call
Wir haben ein spezielles Tool entwickelt, das der Agent aufrufen kann, wenn er entscheidet, dass strukturierte Optionen sinnvoller sind als eine einfache Textantwort. Das LLM übergibt eine Liste von Optionsobjekten (je eines pro Card):
{
"options": [
{
"title": "Scale up payment-gateway",
"description": "Increase replica count from 3 to 6 to absorb current traffic spike. No downtime expected.",
"tag": "Recommended",
"risk": "low",
"effort": "~2 min",
"actionLabel": "Scale up"
},
{
"title": "Option 2: Roll back to v2.4.1",
"description": "Revert the deployment to the last stable version. Resolves regression but requires redeployment.",
"tag": "Immediate",
"risk": "medium",
"effort": "~10 min",
"actionLabel": "Roll back"
}
]
}
Schritt 2: Rendering
Für jede Option wird eine eindeutige Kennung generiert. Anschließend wird ein A2UI-Befehl zur Aktualisierung der Nutzeroberfläche an den Backend-Message-Bus gesendet. Das Frontend abonniert diese Ereignisse und rendert die Cards in Echtzeit innerhalb des Konversations-Threads, sobald sie eintreffen – ohne Page Reload und manuelles Polling.
Schritt 3: Nutzerinteraktion und Intent-Injection
Wenn der Engineer auf eine Aktionsschaltfläche klickt, wird ein Ereignis mit der eindeutigen Kennung der Option an den Agenten zurückgesendet. Der Agent ordnet dies einem vorkonfigurierten Bestätigungssatz zu, zum Beispiel „Ja, skaliere die Replikate des Zahlungsgateways“, und fügt ihn in den Chat-Thread ein, als hätte der Nutzer ihn selbst eingegeben. Dadurch wird der LLM-Loop nahtlos mit der bestätigten, eindeutigen Absicht des Nutzers fortgesetzt.
Schritt 4: Status nach der Auswahl
Sobald der Engineer klickt, aktualisiert die Card ihren eigenen Status: Die Aktionsschaltfläche wird durch ein grünes Häkchen mit der Beschriftung „Ausgewählt“ ersetzt. Diese visuelle Bestätigung macht deutlich, dass die Aktion bestätigt wurde, und verhindert versehentliche doppelte Übermittlungen.
Warum dieses Muster wichtig ist
Dies ist unsere Antwort auf eine Frage, mit der sich jeder AI-SRE-Anbieter auseinandersetzt: Wie viel sollte der Agent autonom erledigen, und wann gibt er an einen Menschen zurück? Unsere Antwort lautet, dass der Übergabemoment genauso reibungslos sein muss wie die ihm vorausgehende Untersuchung. ActionOption Cards sind für diesen Moment konzipiert. Das bedeutet in der Praxis Folgendes:
Visuell leicht erfassbar: Die Cards sind räumlich voneinander getrennt, optisch klar erkennbar und enthalten strukturierte Metadaten. Ein Techniker kann drei Optionen auf einen Blick bewerten, anstatt einen ganzen Textabschnitt lesen zu müssen.
Eindeutige Signalisierung von Risiken und Aufwand: Anstatt die Risikobewertung der Intuition zu überlassen, zeigt der Agent direkt neben jeder Option Daten zu Risiken und Aufwand an – Informationen, die aus Runbooks, historischen Incidentdaten oder seiner eigenen Analyse stammen.
Eindeutige Absicht: Ein angeklickter Button ist einer exakten, maschinenlesbaren Aktion zugeordnet. Es gibt keine Mehrdeutigkeit in der natürlichen Sprache zwischen „skalieren“ und „die Replikate erhöhen“. Das Identifier-to-Sentence-Mapping stellt sicher, dass das LLM genau das erfährt, was der Engineer bestätigt hat.
Fortsetzbarer Agenten-Loop: Da der eingefügte Bestätigungssatz wie jede andere Nachricht wieder in den Chat-Thread eingefügt wird, wird der LLM-Loop ohne Special Case-Handling fortgesetzt. Der Agent setzt seinen Workflow fort, als hätte der Engineer die Antwort ganz normal eingetippt.
Governance auf Klick
Viele AI-SRE-Produkte sprechen von „Human-in-the-Loop“ als Sicherheitskonzept. ActionOption Cards machen dies zur gelebten Realität von UX. Der Engineer genehmigt eine Aktion nicht, indem er „Ja“ in ein Chatfeld eingibt, sondern er klickt auf eine Schaltfläche, die das Risiko, den Aufwand und den Kompromiss auf einen Blick anzeigt. Die Genehmigung erfolgt fundiert und schnell.
Das ist der Unterschied zwischen einem KI-Agenten, der auf ein Produkt aufgesetzt wird, und einem, der in dieses integriert ist. Der Agent erlangt schrittweise Autonomie, und bei jedem Schritt ist der Moment der menschlichen Genehmigung so gestaltet, dass er ebenso klar und schnell ist wie die ihm vorausgehende KI-Untersuchung.
Zurück zu 2:47 Uhr. Die KI hat recherchiert. Drei Optionen werden angezeigt. Ein Klick.
Eine Incident-Response-Plattform hilft Unternehmen dabei, IT-Störungen schnell und effizient zu behandeln, zu verfolgen und zu lösen. Mit der richtigen Plattform können IT-Teams Ausfallzeiten minimieren, die Auswirkungen von Störungen verringern und insgesamt ihre Reaktionszeiten verbessern.
In diesem Artikel stellen wir die fünf besten Incident-Response-Plattformen für 2025 vor – und helfen Ihnen dabei, die passende Lösung für Ihre Anforderungen zu finden.
Diese Liste ist nicht 100 % objektiv – schließlich bieten wir selbst eine vollständige End-to-End-Plattform für Incident-Management an. Dennoch haben wir uns bemüht, die Bewertung so fair wie möglich zu gestalten. Alle aufgeführten Plattformen sind bewährt, robust und in der Lage, sämtliche operativen Anforderungen zu erfüllen. Wir zeigen außerdem Gemeinsamkeiten und Unterschiede auf, um Ihnen die Orientierung zu erleichtern – selbst wenn Sie sich dann doch nicht für uns entscheiden.
Das Wichtigste in Kürze
Die Auswahl des richtigen Incident-Management-Tools ist entscheidend für ein effektives Incident-Management, insbesondere für Unternehmen, die sich mit EU-Vorschriften und aktuellen Änderungen wie dem Auslaufen von Opsgenie auseinandersetzen müssen.
Zu den wichtigsten Funktionen, auf die Sie bei Incident Response und Incident-Management achten sollten, gehören Multi-Channel-Alarmierung, automatisierte Workflows, anpassbare Eskalationsrichtlinien und robuste Integrationen mit bestehenden Systemen.
Führende Plattformen bieten erweiterte Funktionen, die auf verschiedene organisatorische Anforderungen zugeschnitten sind, können jedoch hinsichtlich Kosten und Eignung für unterschiedliche Teamgrößen erheblich variieren.
Bei der Bewertung von Plattformen im Jahr 2026 gibt es verschiedene Kernfunktionen, die für Engineering- und Betriebsteams unverzichtbar sind. Beginnen wir mit den Alarmierungsfunktionen: In erster Linie muss die Alarmierung über mehrere Kanäle möglich sein – sie muss Sprachanrufe, SMS, Push-Benachrichtigungen, E-Mails und Chat-Tools wie Slack oder Microsoft Teams unterstützen – und vollständig ausführbar sein, ohne dass sich der Nutzer anmelden oder zu einer anderen App wechseln muss.
Die Time-to-Response ist entscheidend, und das Vermeiden von Problemen bei diesem Schritt kann den Unterschied zwischen einer geringfügigen Dienstunterbrechung und einem größeren Ausfall ausmachen. Erweiterte Funktionen wie die Deduplizierung von Alarmierungen, intelligente Gruppierung, Vermeidung von Alarmrauschen durch Filterregeln und wiederverwendbare Vorlagen tragen dazu bei, die Alarmmüdigkeit zu verringern und sicherzustellen, dass die Responder nur relevante und wirklich wichtige Alarmierungen erhalten. In den letzten Jahren haben viele Incident-Response-Plattformen auch KI-gesteuerte Funktionen eingeführt, die Alarmierungen automatisch korrelieren, verwandte Signale aufzeigen und mögliche Ursachen vorschlagen, wodurch Teams die durchschnittliche Zeit bis zur Lösung (MTTR) reduzieren können. Einige Plattformen können Protokolle, Metriken und aktuelle Code- oder Bereitstellungsänderungen analysieren, um Incidents in Echtzeit zu untersuchen, Abhilfemaßnahmen wie Neustarts oder Rollbacks empfehlen und strukturierte Zusammenfassungen erstellen, um schneller aus Incidents zu lernen und sich kontinuierlich zu verbessern.
Eine weitere wichtige Komponente ist das Bereitschaftsmanagement. Lösungen sollten eine automatisierte Verwaltung von Dienstplänen mit Unterstützung für Rotationen, Überschreibungen und Übergaben sowie vollständig anpassbare Eskalationsrichtlinien bieten, um sicherzustellen, dass die richtige Person basierend auf Schweregrad, Tageszeit oder anderen dynamischen Bedingungen benachrichtigt wird. Außerdem ist es wichtig, dass die Benutzeroberfläche für alle Mitglieder der Bereitschaftsteams bequem und einfach zu bedienen ist.
Integrationsfunktionen sind entscheidend für die Einbettung des Incident-Response-Prozesses in Ihre bestehenden Tools. Führende Plattformen bieten native Integrationen mit Monitoring- und Observability-Tools (wie Prometheus, Datadog oder PRTG), Log-Aggregatoren (wie Loki), ITSM-Tools (z. B. ServiceNow, Jira Service Management) und CI/CD-Systemen (wie GitHub oder GitLab). Diese Integrationen gewährleisten einen nahtlosen Datenfluss und ermöglichen eine schnelle Kontextgewinnung während eines Incidents.
Statusseiten sind ein weiterer wertvoller Vorteil. Sie ermöglichen es Teams, während Ausfällen transparent mit Nutzern und Stakeholdern zu kommunizieren, wodurch die Belastung des Supports reduziert und Vertrauen aufgebaut wird.
Schließlich ist die Analyse nach einem Incident nicht mehr nur ein nettes Extra. Plattformen sollten die automatisierte Erstellung von Post-Mortem-Berichten unterstützen, indem sie Zeitachsen, Chat-Protokolle, Alarmierungen und Lösungsschritte während des Incidents selbständig erfassen. Viele moderne Incident-Management-Plattformen generieren aus diesen Daten auch automatisch Entwürfe für Post-Mortem-Berichte. Das reduziert den Verwaltungsaufwand und ermöglicht Teams, sich auf Ursachenanalyse und Verbesserungen zu konzentrieren.
Kurz gesagt, eine moderne Incident-Management-Plattform sollte als Kontrollzentrum fungieren – sie sollte eng mit Ihrem Stack verbunden sein, im besten Fall automatisiert und so gestaltet sein, dass sich die Mitarbeiter auf die wichtigsten Entscheidungen konzentrieren können.
ilert: die All-in-One-Lösung für Incident-Management aus Europa
ilert ist eine Incident Response-Plattform, die speziell für moderne DevOps- und SRE-Teams entwickelt wurde. Sie verbindet Alarmierungen, Observability-Daten, Deployments und Infrastrukturdaten über den gesamten Technologie-Stack hinweg, sodass die KI Incidents im vollständigen Kontext untersuchen und die Incident Response-Maßnahmen in einer einheitlichen Umgebung koordinieren kann. Als AI-First-Plattform orientiert sich ilert an einem einfachen Leitprinzip: Sie werden nur dann benachrichtigt, wenn die KI nicht sicher weiterarbeiten kann.
Im Mittelpunkt steht die ilert AI SRE, ein intelligenter Agent, der jede Alarmierung untersucht. Er analysiert Logs, Metriken und aktuelle Änderungen in Ihrem gesamten Observability-Stack, identifiziert Ursachen und ähnliche Incidents aus der Vergangenheit und schlägt Lösungsansätze zur Genehmigung durch den Menschen vor oder löst Incidents autonom, wenn die KI mit hoher Sicherheit entscheiden kann. Ein Governance-Modell bewegt sich schrittweise von „read-only“ über „supervised“ hin zu „autonom“, mit vollständigen Audit-Trails, teambezogenen Agenten und „Human-in-the-Loop“-Kontrollen in jeder Phase.
Die KI deckt den gesamten Incident Response Lebenszyklus ab – von Dienstplänen bis zur Lösung von Incidents. Intelligente Alarmierung reduziert Alarmflut durch KI-gestützte Deduplizierung, dynamische Gruppierung und intelligentes Routing, mit Bestätigung per Push, SMS, Sprache und Chat. Das Bereitschaftsmanagement managt Rotationen, manuelle Überschreibungen und Eskalationsrichtlinien über UI, API und mobile Apps hinweg. Der KI-Sprachagent übernimmt den Erstkontakt, erfasst den Kontext und eskaliert nur bei Bedarf. Die ChatOps-Integration sorgt für eine koordinierte Reaktion über Slack, Microsoft Teams oder Google Chat. Nativ integrierte Statusseiten automatisieren die Kommunikation mit den Beteiligten in Echtzeit. Und KI-generierte Postmortems wandeln Incident-Timelines automatisch in strukturierte, umsetzbare Berichte um.
ilert lässt sich über mehr als 100 vorgefertigte Integrationen mit Monitoring-, Ticketing-, ChatOps- und Infrastruktur-Tools wie Prometheus, Grafana, Datadog, Zabbix, AWS CloudWatch, Jira, ServiceNow, Slack, Microsoft Teams und Google Chat an Ihre bestehende Infrastruktur anbinden, ohne dass eine Migration erforderlich ist.
Als in Deutschland ansässiges Unternehmen ist ilert DSGVO-konform mit EU-Datenresidenz und nach ISO 27001 zertifiziert, was es zur ersten Wahl für datenschutzbewusste Organisationen macht. Es ist eine agilere, kundenorientierte Alternative zu PagerDuty und Opsgenie, der Unternehmen wie REWE digital, Lufthansa Systems, Adesso und Bertelsmann vertrauen, und unterstützt Anwendungsfälle von DevOps und SecOps bis hin zu MSPs und industriellen Betrieben.
PagerDuty: Der Veteran im Incident-Management
PagerDuty gilt seit Langem als Pionier im Bereich Incident-Management. Seit der Gründung im Jahr 2009 hat sich die Plattform zu einer umfassenden Lösung entwickelt – primär für DevOps- und SRE-Teams in großen, komplexen Umgebungen. Sie bietet einen ausgereiften Funktionsumfang, darunter Multi-Channel-Alarmierung, Planung von Bereitschaftsdiensten, Eskalationsrichtlinien und Echtzeit-Tracking von Störungen.
Eine der großen Stärken von PagerDuty ist das umfangreiche Integrations-Ökosystem: die Lösung unterstützt eine große Anzahl Tools wie Datadog, New Relic, AWS CloudWatch, Splunk und viele mehr. Zudem nutzt PagerDuty Event Intelligence: Mit Hilfe von Machine Learning werden irrelevante Alarmierungen unterdrückt, zusammengehörige Ereignisse korreliert und Störungen priorisiert – was Teams hilft, sich auf das Wesentliche zu konzentrieren.
Für große Unternehmen bietet PagerDuty zusätzliche Features wie Runbook Automation, Service Graphs und Business Impact Metrics, um Abhängigkeiten zu verwalten, Auswirkungen besser einzuschätzen und technische Vorgänge mit geschäftlichen Zielen abzugleichen.
Allerdings hat dieser große Funktionsumfang auch seinen Preis: Viele Teams – insbesondere in mittelgroßen Unternehmen oder mit einfacheren Anforderungen – empfinden PagerDuty als überladen und komplex, mit einer steilen Lernkurve und einem Preismodell, das bei wachsendem Team schnell teuer wird.
Kurz: PagerDuty ist und bleibt eine leistungsfähige und bewährte Plattform – besonders für große Unternehmen mit hohem Automatisierungs- und Integrationsbedarf. Doch für Teams, die eine agilere, kosteneffizientere und datenschutzkonforme Lösung suchen – vor allem in Europa – gibt es inzwischen moderne Alternativen, die besser zu aktuellen Anforderungen passen.
xMatters ist ein etablierter Anbieter im Bereich Incident-Management mit einem starken Fokus auf Workflow-Automatisierung und ereignisgesteuerte Orchestrierung. Die Plattform richtet sich an DevOps-, ITOps- und Business-Continuity-Teams und ermöglicht es, individuelle Workflows zu erstellen, die Monitoring-Systeme, Benachrichtigungskanäle, Ticketing-Tools und mehr miteinander verbinden – alles über eine Low-Code-Oberfläche.
Zu den Incident-Response-Funktionen von xMatters gehören Multi-Channel-Alarmierung, Bereitschaftsplanung, Eskalationen und automatisierte Reaktionen. Das Besondere an xMatters ist die Möglichkeit, Workflows zu definieren, die bei bestimmten Bedingungen automatisch ausgelöst werden.
Allerdings kann xMatters den Eindruck vermitteln, dass es sich mehr auf die Prozessautomatisierung als auf die praktische, anwenderfreundliche Behebung von Störungen konzentriert.
IT-Teams, die eine intuitive UI und eine enge Verzahnung mit modernen DevOps-Prozessen suchen, könnten es als weniger direkt empfinden als alternative Lösungen wie ilert oder PagerDuty. Auch die Benutzeroberfläche und die Einrichtung gelten als komplex – insbesondere für kleinere Teams ohne dedizierte Experten für das Setup von Tools.
Für Unternehmen mit starkem Fokus auf ITSM und Prozessautomatisierung ist xMatters dennoch eine leistungsstarke und individuell anpassbare Lösung – für reine Incident-Response jedoch manchmal überdimensioniert.
Grafana IRM: Integriertes Incident-Management für das Grafana-Ökosystem
Grafana IRM (Incident Response & Management) ist die neue integrierte Lösung von Grafana Labs, die Grafana OnCall und Grafana Incident zu einer einzigen cloudbasierten Plattform vereint. Sie wurde speziell für IT-Teams entwickelt, die bereits auf Grafana Cloud für Observability setzen. Die Plattform deckt den gesamten Lebenszyklus einer Störung ab – von der Erkennung bis zur Behebung.
Ein wesentlicher Vorteil liegt in der nahtlosen Integration mit Tools wie Loki, Tempo und Prometheus. IT-Teams können Störungen direkt über ihre Dashboards erstellen, verfolgen und beheben – ohne zwischen Tools wechseln zu müssen. Die Plattform bietet integrierte Dienstplan-Verwaltung, Eskalationen, Incident-Tracking und anpassbare Workflows zur Steuerung von Benachrichtigungen, Eskalationen und Postmortems. Alle Beteiligten werden dabei stets über native Benachrichtigungen informiert.
Für Teams, die bereits mit Grafana Cloud arbeiten, bietet IRM Komfort und Geschwindigkeit. Es reduziert die Anzahl der Tools, verringert die Komplexität der Einbindung und sorgt dafür, dass die Reaktion auf Störungen eng mit der Überwachung und Protokollierung verknüpft bleibt. Der Einstieg ist unkompliziert, das Setup schnell erledigt – ideal für schlanke Incident-Prozesse.
Allerdings ist die Plattform stark an die Grafana Cloud gebunden. Wer hybride oder nicht-Grafana-Stacks nutzt, stößt schnell an Grenzen. Auch fortgeschrittene Features wie KI-gestützte Deduplizierung, Sprach-Routing oder Mandantenfähigkeit fehlen – Funktionen, die dedizierte Plattformen wie ilert oder PagerDuty besser abdecken.
Kurzum: Eine starke Lösung für Grafana-Nutzer – aber eher Ergänzung als Ersatz für komplexe oder heterogene Umgebungen.
OpsGenie: Die Lösung für Nutzer von Jira-Service-Management
Opsgenie, einst eine beliebte Lösung für Incident-Alarmierung und Bereitschaftsmanagement, ist seit langem Teil des Atlassian-Ökosystems. Bekannt für seine übersichtliche Benutzeroberfläche, seine solide Logik für Alarmierungsweiterleitung und seine enge Integration mit Jira und Confluence, hat Opsgenie vielen DevOps- und IT-Teams gute Dienste geleistet – insbesondere denen, die bereits in Atlassian-Produkte investiert hatten.
Die Plattform bot Kernfunktionen wie Bereitschaftsplanung, Multi-Channel-Alarmierung, Eskalationsrichtlinien und Integrationen mit gängigen Überwachungstools wie Datadog und Prometheus. Dank der Funktionen zur Anpassung von Alarmierungen und zur Darstellung Timeline von Incidents war sie eine praktische Wahl für die Verwaltung kritischer Ereignisse und unterstützte Collaboration-Tools wie Slack.
Opsgenie wird jedoch auslaufen und in die umfassendere ITSM-Suite von Atlassian, vor allem Jira Service Management (JSM), integriert werden. Diese Umstellung stellt Teams, die Opsgenie als eigenständiges, leichtgewichtiges Tool für die Incident Response genutzt haben, vor Herausforderungen. Die engere Kopplung mit JSM erhöht die Komplexität und ist möglicherweise nicht für agile DevOps-Teams oder Dienstleister geeignet, die Flexibilität und Geschwindigkeit suchen.
Atlassian hat den Verkauf neuer eigenständiger Opsgenie-Abonnements im Juni 2025 eingestellt und plant, den Support bis April 2027 vollständig einzustellen, um Unternehmen zur Migration zu Jira Service Management oder alternativen Plattformen für das Incident Management zu bewegen.
Infolgedessen suchen viele Unternehmen nun aktiv nach einer Alternative zu Opsgenie – einer Lösung, die die gleiche Zuverlässigkeit mit einem reaktionsschnellen Support, einer dedizierten Roadmap und größerer Flexibilität bietet. Plattformen wie ilert haben sich als erste Wahl herausgestellt und bieten nahtlose Migrationspfade, GDPR-Konformität sowie erweiterte Funktionen für Alarmierungen, Zeitplanung und Automatisierung, die über das Angebot von Opsgenie hinausgehen. Wenn Sie JSM verwenden und dies auch weiterhin tun möchten, ist Opsgenie nach wie vor eine hervorragende Lösung, die bald in die vertraute Plattform integriert wird.
Suchen Sie nach einer Alternative zu Opsgenie? Erfahren Sie, wie der Wechsel zu ilert funktioniert, und erhalten Sie umfassende Migrationsunterstützung von unserem Customer Success Team.
Zusammenfassung
Die Wahl der richtigen Plattform für die Incident Response ist entscheidend für die Aufrechterhaltung der Zuverlässigkeit Ihrer Dienste und die schnelle Behebung von Incidents. Jede der in diesem Blogbeitrag vorgestellten Plattformen bietet einzigartige Stärken und Funktionen, wodurch sie sich für unterschiedliche organisatorische Anforderungen eignen.
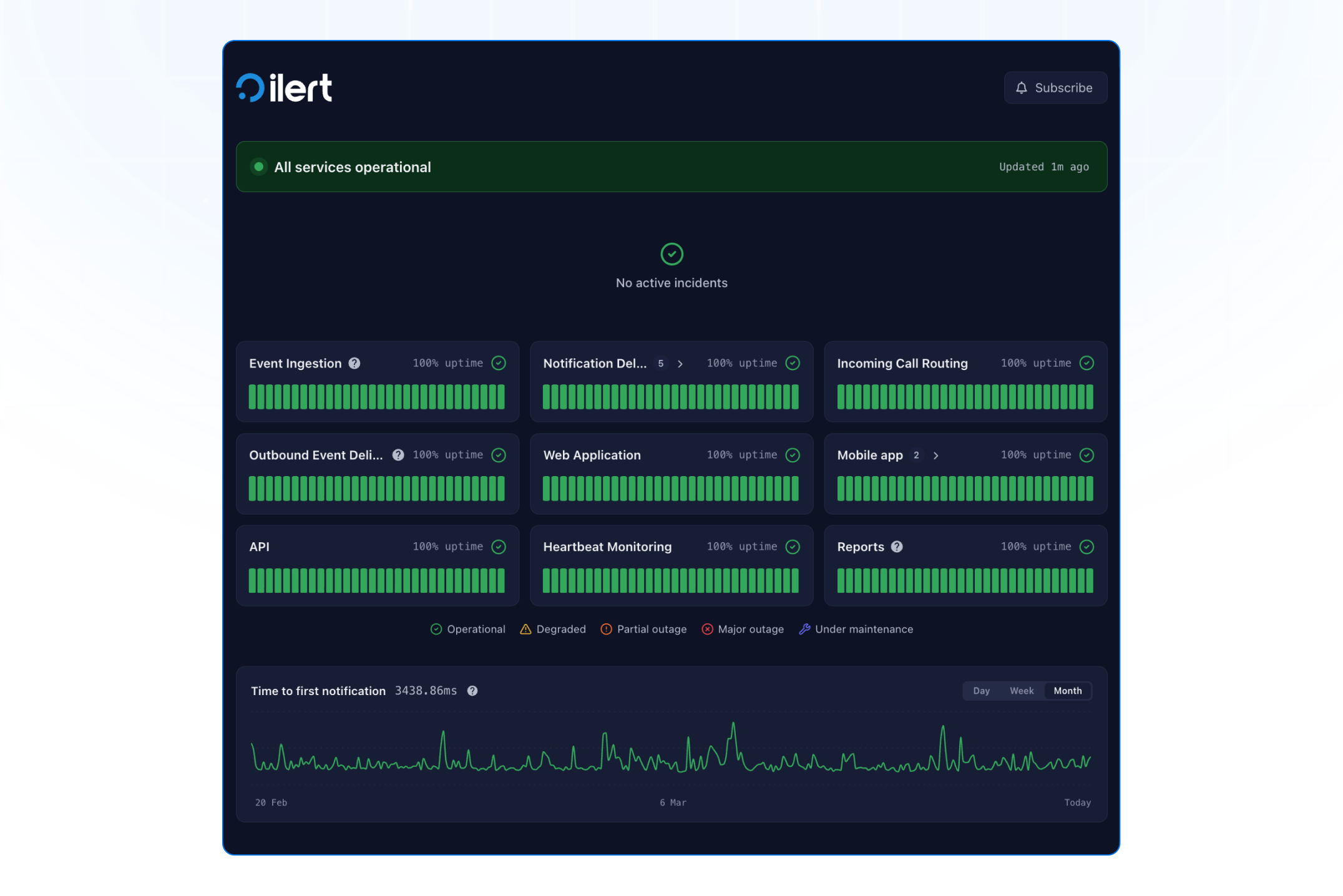
Unsere Statusseiten haben jetzt ein neues Design und sind wesentlich übersichtlicher gestaltet.
Die dem Publikum zugänglichen Statusseiten wurden von Grund auf neu gestaltet: übersichtlichere visuelle Gestaltung, bessere Informationshierarchie und schnellerer Zugriff auf das, was während eines Incidents wichtig ist. Hier sind die Neuerungen:
Optimierte Incident-Cards: Erweiterbare Zeitleisten zeigen den vollständigen Verlauf aller Updates mit den betroffenen Diensten auf einen Blick, sodass Ihre Nutzer immer genau wissen, was betroffen ist und was unternommen wird.
Übersichtlichere Historie vergangener Incidents: Incidents sind nun nach Datum gruppiert, lassen sich mit vollständigen Zeitleisten erweitern und jeder Eintrag ist mit einer eigenen Detailansicht verlinkt.
Sofortiger Status auf einen Blick: Ein Statusbanner in voller Breite mit Live-Anzeige informiert Besucher über den aktuellen Systemstatus, sobald sie auf der Seite landen.
Das Redesign ist vollständig responsiv und für die an allen Details interessierten Nutzer entworfen, die Ihre Statusseite während eines Ausfalls aufrufen: alles ist klar und verständlich dargestellt.
ChatOps
Unterstützung von Google Chat
Unsere ChatOps-Funktion hat Teams schon immer dabei geholfen, stets auf dem gleichen Stand zu bleiben, indem es ihnen ermöglichte, Incidents zu verwalten, ohne ihr jeweiliges Chat-Tool verlassen zu müssen. Jetzt erweitern wir diesen Bereich: Google Chat wird neben Slack und Microsoft Teams offiziell unterstützt.
Ihr Team kann nun:
Alarmierungen in Kanälen empfangen, dank der neuen Google Chat-Aktion „Alarmierungen“
Auf Alarmierungen reagieren: Annehmen, Eskalieren, Lösen, Umleiten, Zusammenführen
Nahtloses User-Mapping nutzen, damit Aktionen im Namen des richtigen Teammitglieds ausgeführt werden
Sofort nachsehen, wer gerade dienstbereit ist – ohne Dashboard, ohne Tab-Wechsel, ohne Verzögerung
In Sekundenschnelle einen War Room einrichten, damit die Incident Response von der ersten Minute an strukturiert abläuft.
Ganz gleich, ob Ihr Team Slack, Teams oder Google Workspace nutzt – ChatOps sorgt dafür, dass das Incident-Management dort stattfindet, wo Ihr Team bereits zusammenarbeitet.
Event Flows
Knoten „Transform Event“
Sie können nun die Eigenschaften eines Events wie Priorität, Labels und Zusammenfassungen ändern und ergänzen: direkt in Ihren Event Flows mithilfe des neuen „Transform Event“-Knotens. Die Verwaltung erfolgt komplett über Terraform, sodass eine versionskontrollierte Orchestrierung von Incidents möglich ist.
Ausführungsprotokolle des Transform-Nodes
Sie können jetzt genau nachvollziehen, was innerhalb eines Transform Nodes während der Ausführung eines Event Flows passiert ist. Dadurch lassen sich Regeln schneller debuggen und Sie können besser verstehen, wie Events während der Verarbeitung angepasst werden.
Zwei neue Protokolleinträge sind verfügbar:
„Transform Error“: Wird erfasst, wenn eine Regel zur Laufzeit fehlschlägt, mit einem maschinenlesbaren Fehlercode, einer kurzen Beschreibung und der spezifischen Regel, die das Problem verursacht hat.
„Transformed“: Wird einmalig ausgegeben, nachdem alle Regeln verarbeitet wurden, jedoch nur, wenn mindestens eine relevante Änderung vorliegt.
Beide Einträge sind direkt im Ausführungsprotokoll zugänglich und bieten eine klare Nachvollziehbarkeit vom eingehenden Roh-Event bis zum transformierten Event.
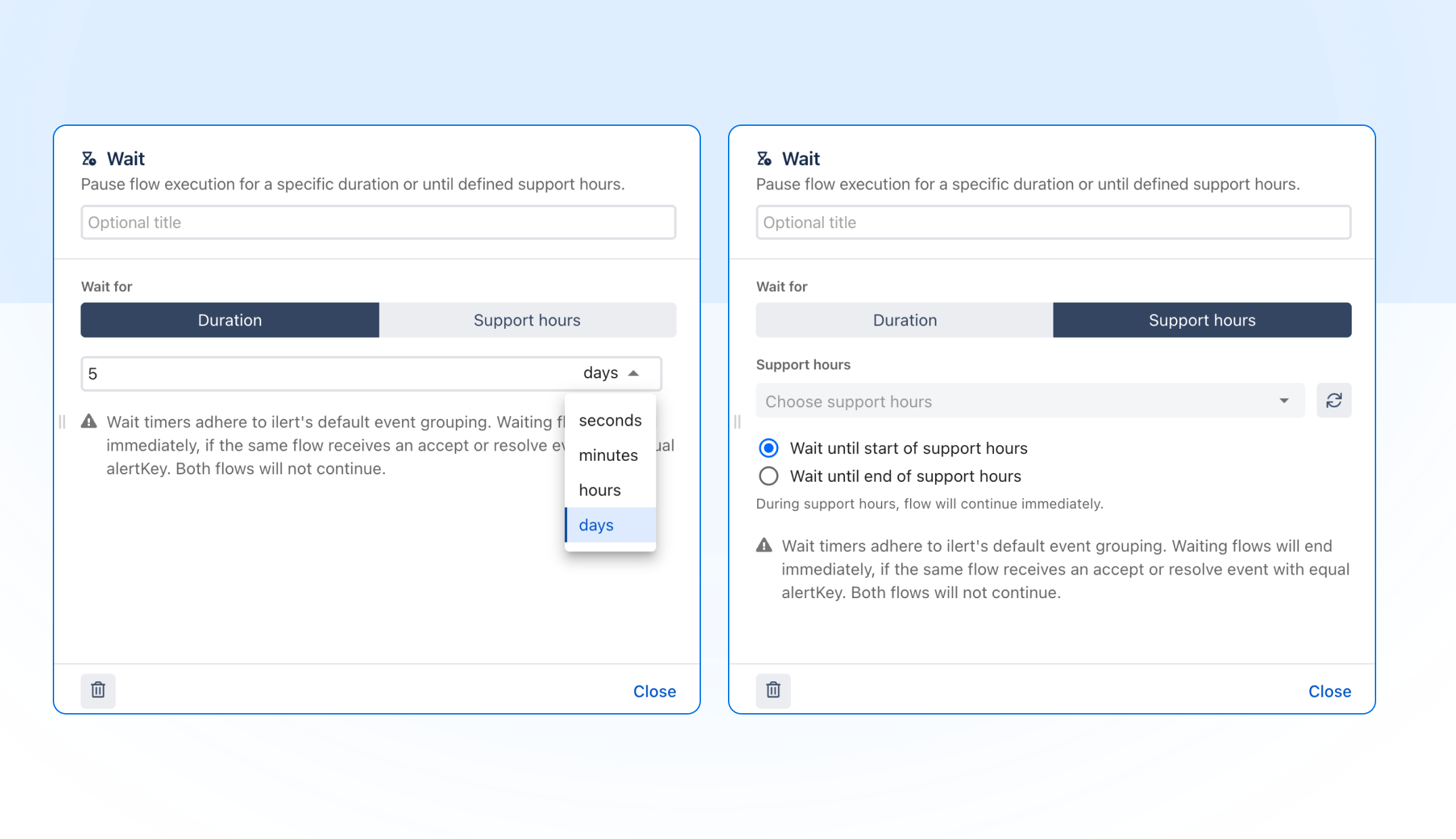
Wait Nodes unterstützen nun Betriebszeiten und mehrtägige Laufzeiten
Event Flows können nun basierend auf Ihren konfigurierten Betriebszeiten angehalten und fortgesetzt werden, sodass die Routing-Logik berücksichtigt, wann Ihr Team tatsächlich verfügbar ist, und nicht nur, ob eine Bedingung erfüllt ist. Wartezeiten können nun auch in Tagen festgelegt werden, wodurch die bisherige Begrenzung auf Stunden aufgehoben wird.
Terraform
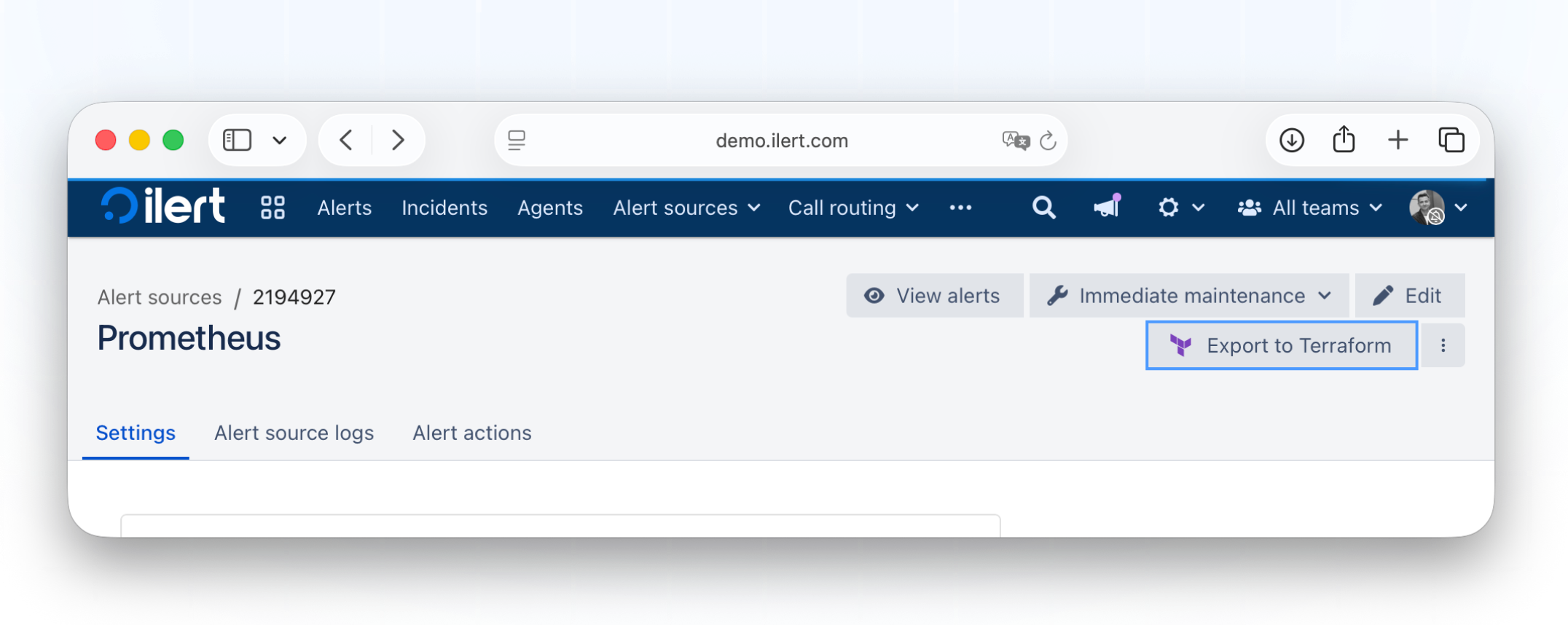
Ressourcen in Terraform exportieren: vom UI mit nur einem Klick zum Code
Wir machen die Einführung von Infrastructure-as-Code einfacher. Mit der neuen Funktion „Export in Terraform“ können Sie mit einem einzigen Klick direkt von jeder Ressourcendetailseite aus gültige HCL-Ressourcenblöcke generieren. Überbrücken Sie die Lücke zwischen Benutzeroberfläche und Code im Handumdrehen und beschleunigen Sie Ihre IaC-Workflows, ohne Konfigurationen manuell schreiben zu müssen.
Alarmierung und Incident-Management
Teams in Eskalationsrichtlinien aufnehmen
Sie können jetzt Teams in Eskalationsrichtlinien aufnehmen – zusätzlich zu einzelnen Nutzern und Dienstplänen. Dadurch reduziert sich der Konfigurationsaufwand und die Verantwortlichkeiten sind auch bei wachsender Skalierung klarer geregelt.
Services und Schweregrade: end-to-end
Definieren Sie Standardwerte für Service und Schweregrad in Ihren Alarmierungsquellen, überschreiben Sie sie in Echtzeit über die Event API und sehen Sie sich die aktuellen Impact-Level direkt in der Alarmierungs-Detailansicht an. Profitieren Sie von intelligenten, vollständig überschreibbaren Standardwerten – die genau dort sichtbar sind, wo es am wichtigsten ist.
Mehrere Responder gleichzeitig hinzufügen
Sie können nun mehrere Responder oder Ziele gleichzeitig direkt aus der Alarmierungs-Detailansicht auswählen und hinzufügen – das mühsame Hinzufügen einzelner Einträge entfällt.
Berichte über Alarmierungen können nun nach Labels gefiltert werden
Sie können Berichte über Alarmierungen nun nach Labels filtern. Das macht es einfacher, Berichte auf einen bestimmten Service, ein bestimmtes Team oder eine bestimmte Umgebung einzugrenzen.
Zugang & Rollen
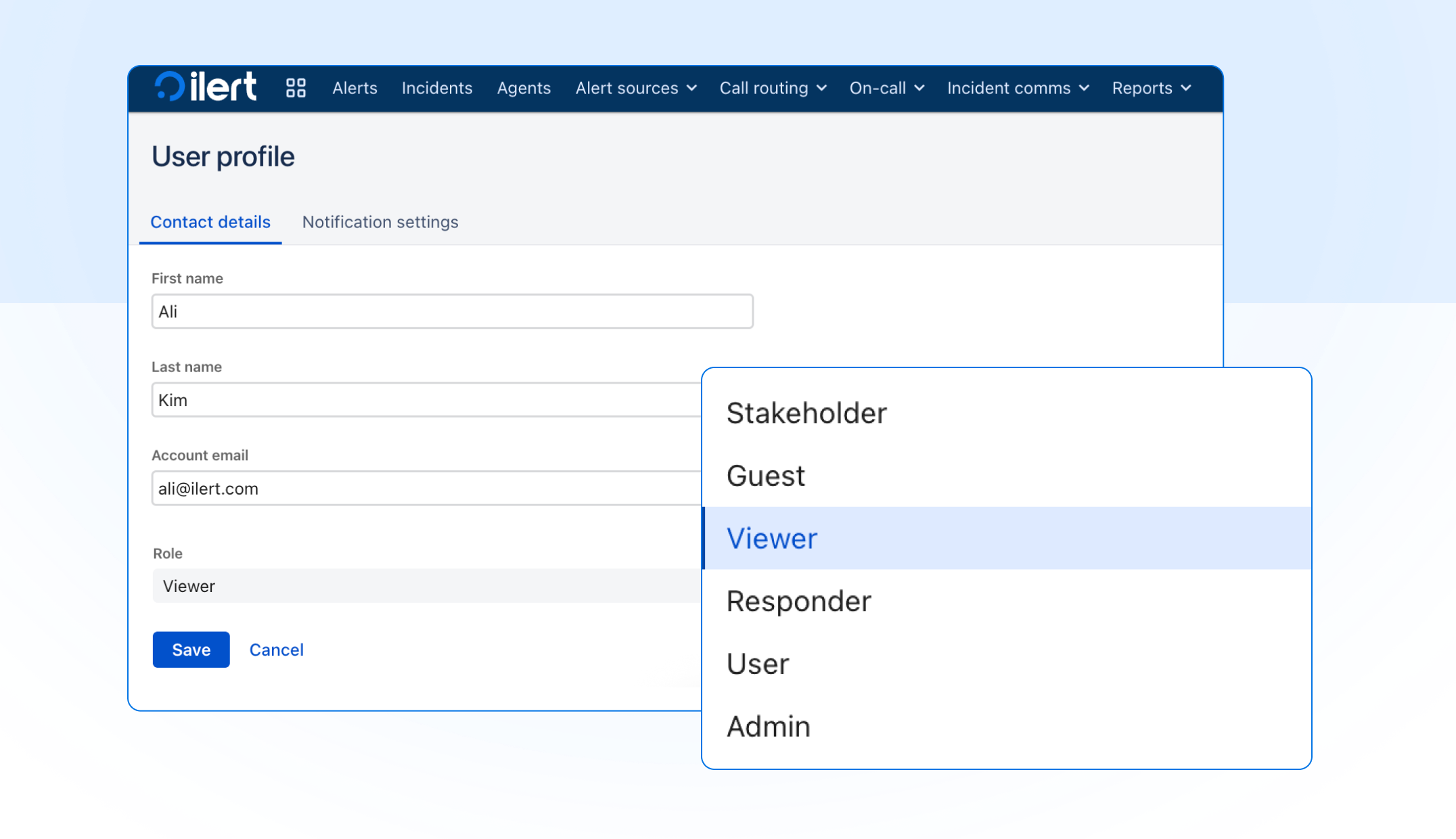
Einführung der Rolle „Viewer“
Lernen Sie die neue Rolle „Viewer“ kennen, die für interne Nutzer entworfen wurde, die vollständige operative Transparenz benötigen, jedoch ohne das Risiko, Änderungen vornehmen zu können. Viewer erhalten kontoweiten, schreibgeschützten Zugang zu allen Incidents, Alarmierungen, Services, Konfigurationen (einschließlich Dienstplänen, Eskalationsrichtlinien und Alarmierungsquellen) sowie zu Berichten.
Die Rolle ist ideal für Engineering-Manager, Führungskräfte und Customer Support Leads, die tiefere Einblicke in Abläufe benötigen, während die operative Kontrolle fest in den richtigen Händen bleibt.
Abrechnung
Administratoren können nun Seats direkt erwerben
Wenn das Hinzufügen eines neuen Nutzers einen zusätzlichen Seat erfordern würde, weist ilert im Voraus darauf hin und bittet um Bestätigung, bevor der Vorgang ausgeführt wird. Über eine spezielle Einstellung auf der Seite „Kontoeinstellungen“ (zugänglich für Kontoinhaber) können Sie steuern, ob Administratoren zusätzliche Seats kaufen dürfen. Zusätzliche Seats werden immer anteilig berechnet. Der Abrechnungszeitpunkt hängt von Ihrem Tarif ab:
Rechnungs-Kunden: in der nächsten Rechnung
Self-Service-Monatsabos: in der nächsten Rechnung
Self-Service-Jahresabos: sofortige Berechnung
Zahlung auf Rechnung für Self-Service-Jahresabos
Beginnend mit deutschen Kunden erweitern wir die Möglichkeit für Zahlung auf Rechnung schrittweise auf weitere Länder, einschließlich der EU und der USA. Kunden mit einem Jahresabonnement von 2.000 € oder mehr können per Rechnung bezahlen: der Ablauf ist vollständig automatisiert, es sind keine manuellen Schritte erforderlich.
Hinweis: Änderungen an den Rechnungen werden nicht unterstützt.
Anruf Routing
Transkriptionen von Voicemails unterstützen nun mehrere Sprachen
Die Transkription von Voicemails im Call-Flow ist jetzt nicht mehr auf nur eine einzige Sprache beschränkt. ilert erkennt und transkribiert Voicemails nun in der Sprache, in der sie hinterlassen wurden.
Mobile Version
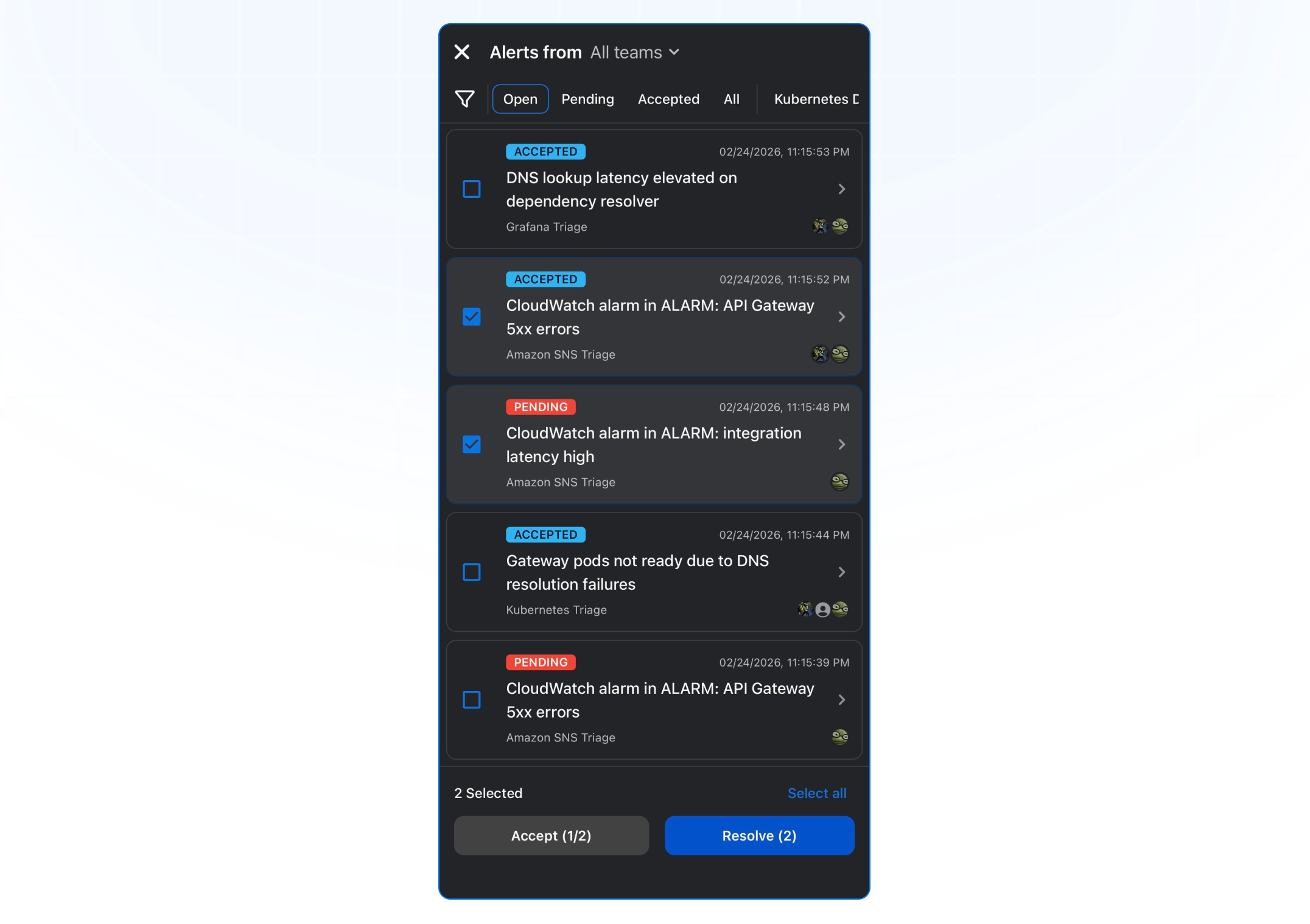
Neugestaltete Detailansicht von Alarmierungen
Wir haben die mobile Detailansicht von Alarmierungen optimiert, damit Sie mehr Platz für das Wesentliche haben und Incidents auch unterwegs schneller bearbeiten können.
Die Alarmierungszusammenfassung, die Chips-Leiste und die Tabs sind jetzt übersichtlicher angeordnet und haben ein klareres Layout. Die Chips-Leiste zeigt standardmäßig bis zu zwei Zeilen und verfügt über ein Label-Icon für mehr Übersicht. Die Actions-Leiste bleibt am unteren Bildschirmrand fixiert, sodass wichtige Aktionen jederzeit griffbereit sind. Weniger Scrollen, mehr Kontext, schnellere Entscheidungen garantiert.
Mehrere Alarmierungen gleichzeitig bestätigen und lösen
Sie können nun mehrere Alarmierungen auswählen und diese mit einem Tippen direkt aus der Liste der Benachrichtigungen auf dem Mobilgerät bestätigen oder lösen.
Integrationen
Benutzerdefinierte HTTP-Header für Webhook-Alarmierungsaktionen
Sie können jetzt benutzerdefinierte Header für ausgehende Webhook-Integrationen definieren. Das ist besonders nützlich, um Authentifizierungstokens, API-Keys oder andere Metadaten zu übermitteln, die Ihr empfangender Endpoint erwartet.
Neue Integrationen:
WhaTap: Eine KI-native Observability-Plattform. Als SaaS-basierter Anbieter für einheitliches IT-Monitoring bietet sie umfassende Überwachung über eine Vielzahl von IT-Umgebungen hinweg.
Phare Uptime: ist ein zuverlässiger, datenschutzorientierter Monitoring-Service, der Ihre Websites, APIs und SSL-Zertifikate stets genau überwacht.
SysAid: Eine AI-native ITSM-Plattform, die entwickelt wurde, um die aufwendigen Aufgaben moderner IT zu automatisieren. Sie nutzt integrierte KI, um Aufgaben zu priorisieren, Ticketverläufe zusammenzufassen und Endnutzern sowie IT-Admins sofortige Lösungen bereitzustellen.
Level: Eine moderne Remote-Monitoring- und Management (RMM)-Plattform, entwickelt für IT-Teams und MSPs, die effizienter arbeiten und Problemen proaktiv einen Schritt voraus sein wollen.
Hoppla! Beim Absenden des Formulars ist etwas schief gelaufen.
Unsere Cookie-Richtlinie
Wir verwenden Cookies, um Ihre Erfahrung zu verbessern, den Seitenverkehr zu verbessern und für Marketingzwecke. Erfahren Sie mehr in unserem Datenschutzrichtlinie.



.png)
.png)
.png)
.png)
.png)
.png)