Einleitung
Wenn die besten Ingenieur:innen unter Burnout leiden, sich die MTTR seit Jahren nicht verbessert, trotz einer stetig wachsenden Tool-Landschaft und sich jede angeblich „KI-gestützte“ Magie am Ende als kaum mehr als Regex mit Marketing entpuppt, ist es Zeit für eine unbequeme Wahrheit.
Wirklich KI-getriebenes Incident Management ist heute erstmals realistisch umsetzbar. Doch 90 % aller Teams werden sie falsch einführen.
Dieser Leitfaden zeigt, wie du zu den 10 % gehören kannst, die es richtig machen: mit einer schrittweisen Einführung agentischen Incident Managements – von KI-unterstützten Workflows bis hin zu zunehmend autonomen Betriebsmodellen.
Für diesen Prozess, werden drei Autonomie Level (L1–L3) definiert:
- Auf Level 1 agiert KI als Co-Pilot, der Empfehlungen gibt, während Menschen die vollständige Kontrolle behalten;
- auf Level 2 führen KI-Agenten bestimmte Aktionen unter menschlicher Anleitung oder innerhalb vordefinierter Leitplanken aus;
- auf Level 3 bewältigen Agenten Routine-Incidents durchgängig und beziehen Menschen nur bei Bedarf ein. Höhere Autonomiestufen zu erreichen verspricht eine deutlich geringere Mean Time to Resolution (MTTR) und weniger 3-Uhr-nachts-Weckrufe für triviale Fixes.

Jede Stufe bringt spezifische technische Anforderungen und Risikoabwägungen mit sich, die wir in diesem Leitfaden detailliert erläutern.
Der Leitfaden ist in klar strukturierte, praxisnahe Kapitel gegliedert:
- den aktuellen Stand des Incident Managements
- die Entwicklungen, die KI-gestützte, agentische Reaktionen heute realistisch machen
- eine Zukunftsperspektive für autonomes Incident Handling
- Referenzarchitekturen und Sicherheitsmodelle für die Umsetzung
- Praxisbeispiele, in denen Autonomie bereits produktiv eingesetzt wird
- eine schrittweise Einführungs-Roadmap
- geeignete Erfolgskennzahlen
- Ansätze zur Risikominimierung
- Checklisten für die Auswahl und Beschaffung
- eine strategische Einordnung und einen Ausblick
Im Mittelpunkt stehen durchgehend klare, umsetzbare Erkenntnisse für CTOs, SRE-Verantwortliche und IT-Führungskräfte, die KI-Agenten gezielt einsetzen möchten, um ihr Incident Management zu unterstützen oder schrittweise zu automatisieren.
Aktueller Stand des Incident Managements
Viele Organisationen verlassen sich noch immer auf manuelle, stark menschenzentrierte Incident-Management-Workflows. Kommt es zu Ausfällen, werden Ingenieur:innen häufig in ein Labyrinth aus Dashboards, Logs und Tickets gerufen und müssen unter hohem Druck zwischen Tools und Kommunikationskanälen wechseln. Dieser reaktive und manuelle Ansatz bei der Ursachenanalyse führt zu längeren Lösungszeiten und höheren Betriebskosten. Zwar existieren bereits gewisse Automatisierungen – beispielsweise regelbasierte Skripte, die einen Service neu starten, wenn ein bekannter Schwellenwert überschritten wird –, doch diese sind in der Regel statisch. Es fehlt Ihnen die adaptive Fähigkeit, neue Probleme zu bewerten oder mehrere Signale miteinander zu korrelieren.
Was bedeutet das konkret? Kritische Incidents erfordern weiterhin Menschen, die Daten interpretieren und Entscheidungen treffen.
Die Schwachstellen des heutigen Ansatzes sind kaum zu übersehen:
Alarmflut und Alarmmüdigkeit: Teams werden von Alarmen überrollt, viele davon ohne Kontext oder mehrfach ausgelöst. Wertvolle Zeit geht in der Triage verloren, während relevante Probleme im Rauschen untergehen.
Datensilos und fehlender Kontext: Monitoring-Tools, Logs, Metriken und Code-Repositories liefern jeweils nur Ausschnitte des Gesamtbilds. Ingenieur:innen müssen diese Informationen mühsam selbst zusammenführen. Ein zentrales System, das den Incident automatisch ganzheitlich einordnet, fehlt.
Menschliche Engpässe: Die Weitergabe über Support-Stufen (L1 → L2 → L3) ist langsam. First-Level-Teams sind häufig mit der Ticketaufnahme und grundlegenden Analysen beschäftigt, was die Einbindung der passenden Expert:innen verzögert. In der Zwischenzeit steigen die Kosten durch Ausfallzeiten weiter an.
Kurz gesagt: Klassisches Incident Management ist stark arbeitsgetrieben, und die Ursachenanalyse nimmt einen großen Teil des Incident-Lebenszyklus ein. Genau an diesem Punkt kann KI einen spürbaren Unterschied machen.
Warum AI-gestütztes agentenbasiertes Incident Management heute realisierbar ist
Mehrere zentrale Entwicklungen machen den Einsatz von AI-Agenten im Incident Management heute praktikabel – in einer Form, die es so bislang nicht gab.
Advances in large language models (LLMs)
Frameworks zur Tool-Integration
Verfügbarkeit von Kosten und Rechenleistung
Kulturelle Akzeptanz und organisatorische Reife
Fortschritte in large language models (LLMs):
Modelle wie GPT-4 und GPT-5 können Logs, Metriken und Code-Diffs lesen und verstehen, sich Schritt für Schritt durch typische Fehlersuchen arbeiten und komplexe Sachverhalte verständlich zusammenfassen. . Mit Chain-of-Thought-Prompting und Fine-Tuning lassen sich auch mehrstufige Vorgehensweisen abbilden – genau das, was für Triage und Behebung von Incidents nötig ist.
Frameworks zur Tool-Integration:
Neue Frameworks und Protokolle schließen die Lücke zwischen KI und operativen Daten. Standards wie das Model Context Protocol (MCP) stellen KI-Agenten aktuelle Telemetrie, Metriken und Code-Änderungen in Echtzeit zur Verfügung und lösen so das Problem veralteter Daten. Orchestrierungsschichten (z. B. LangChain, Semantic Kernel oder individuelle Stacks wie Hive) ermöglichen es Agenten, sicher mit APIs und externen Tools zu interagieren — wie etwa mit Observability-Plattformen, CI/CD-Pipelines, Repositories, Wissensdatenbanken und Ticketing-Systemen.
Verfügbarkeit von Kosten- und Rechenleistung:
Cloud-Anbieter und spezialisierte Hardware haben es möglich gemacht, fortschrittliche KI-Modelle in operativen Echtzeit-Szenarien einzusetzen. In den Jahren 2023 bis 2025 sind die Inferenzkosten für LLMs deutlich gesunken, während gleichzeitig On-Premise- und Open-Source-Modelle an Bedeutung gewonnen haben, insbesondere für Teams mit hohen Anforderungen an Datenschutz und Governance. Dadurch ist kontinuierliche Echtzeitanalyse heute nicht mehr nur den größten Unternehmen vorbehalten.
Kulturelle Akzeptanz und organisatorische Reife:
DevOps- und SRE-Praktiken treiben Automatisierung an und fordern manuelle Routinearbeit zu reduzieren. In vielen Organisationen besteht heute eine klare Bereitschaft, wiederkehrende Aufgaben an Maschinen zu übergeben und menschliche Expertise auf wertschöpfende Engineering-Arbeit zu konzentrieren. Gleichzeitig sind Incident-Management-Prozesse deutlich stärker standardisiert (on-call Management, Runbooks und strukturierte Post-Mortems) und bieten damit eine klare Grundlage, an die KI sinnvoll andocken kann. Zudem ist das Vertrauen in KI gewachsen, nicht zuletzt durch ihre sichtbaren Erfolge in der Softwareentwicklung und im Customer Support.
Kurz gesagt: Die technologische Basis (leistungsfähige KI-Modelle und zuverlässige Integrationsmechanismen) und der operative Druck (Geschwindigkeit und Skalierbarkeit) sind heute erstmals im Einklang.
KI-Agenten können nun eine echte Rolle in der Incident Response übernehmen. Etwas, das vor wenigen Jahren noch nicht realistisch war. Die folgenden Abschnitte zeigen, wie sich dies effektiv und sicher umsetzen lässt.
Unsere Vision: Autonomes IR mit menschlicher Aufsicht
Stelle dir eine Zukunft im Incident-Management vor, in der KI-Agenten Incidents end-to-end lösen und Menschen nur benachrichtigt werden, wenn es wirklich nötig ist.
Die Vision für agentic Management ist, dass ein intelligenter Agent Alarme 24/7 analysiert, Anomalien diagnostiziert, Korrekturmaßnahmen ergreift und Ergebnisse kommuniziert – alles autonom, außer bei unbekannten Szenarien oder Entscheidungen, die menschliches Urteil erfordern.
Praktisch bedeutet das: Routine-Ausfälle (z. B. abgestürzter Service, hängender Prozess oder Fehlkonfiguration) werden vom Agenten in wenigen Momenten erkannt und behoben. Nur wenn der KI-Agent das Problem nicht selbstständig lösen kann, wird eine Benachrichtigung gesendet.
In diesem Zielzustand verhält sich der KI-Agent wie ein erfahrener Ingenieur, der nie schläft. Er beobachtet Metrics und Logs für Frühwarnsignale, gleicht jüngste Änderungen ab (Deployments, Konfigurations-Updates) und identifiziert wahrscheinliche Ursachen jeder Abweichung. Erkennt er ein bekanntes Fehler-Muster, führt er kontrolliert und unmittelbar die dokumentierte Maßnahme aus, beispielsweise ein Rollback des fehlerhaften Releases ausführen oder eine Komponente neu starten.
Während des gesamten Prozesses hält der Agent Stakeholder auf dem Laufenden, indem er Kommunikationskanäle automatisch aktualisiert. Er könnte z. B. eine Slack-Nachricht oder Statusseiten-Aktualisierung posten wie: „FYI: Service X hatte um 02:13 UTC ein Memory-Leak und wurde automatisch neu gestartet. Die Nutzer-Auswirkung war minimal (5 % der Requests schlugen 90 Sekunden lang fehl). Ursachenanalyse folgt.“
Der Agent agiert im Grunde als Incident Commander, Resolver und Kommunikator in einem.
Referenzarchitektur für agentenbasiertes IR
Die Einführung von agentic Incident-Management erfordert eine durchdachte Architektur, die KI-Agenten in die bestehende IT-Landschaft integriert und dabei Sicherheit und Zuverlässigkeit priorisiert. Die Referenzarchitektur umfasst mehrere zentrale Komponenten und Designprinzipien, darunter:
- Teamspezifische Agenten
- Sichere Integration und Kontexterfassung
- Orchestrierungsschicht und Steuerungsebene
- Observability und Feedback-Mechanismus
Team-spezifische Agenten
Anstatt auf eine allwissende KI zu setzen, betreiben Organisationen ein Netzwerk spezialisierter Agenten, die jeweils auf ein Team oder einen Service-Bereich zugeschnitten sind. So könnten Sie z. B. einen Database Ops Agent, einen Payment Service Agent oder einen Network Infrastructure Agent betreiben – jeweils trainiert auf die Runbooks, Architektur, Incidents und Metriken seines Bereichs.
Ein enger Scope erhöht Genauigkeit und Sicherheit, da ein Agent mit Fokus auf eine Domäne seltener irrelevante Aktionen ausführt. Diese Mehode spiegelt auch die bestehende On-Call-Praxis wider, in der Expertise nach Services aufgeteilt ist.
Agenten können zusammenarbeiten oder aneinander übergeben, wenn ein Incident mehrere Domänen betrifft, operieren jedoch jeweils innerhalb klar definierter Grenzen.
Agenten können zusammenarbeiten oder aneinander übergeben, wenn ein Incident mehrere Domänen betrifft, operieren jedoch jeweils innerhalb klar definierter Grenzen.
LLM-basierte Reasoning Engine, die Incident Kontext erhält und Ursache sowie Lösung ableitet.
Wissensbasis der Domäne (Runbooks, frühere Incident Reports, Dokumentationen), die der Agent abfragt, um Antworten auf Fakten zu stützen.
Toolintegrationen, z.B. MCP Server zum Abfragen von Monitoringdaten, zum Ausführen von Skripten, zum Neustarten von Services, zum Öffnen von Tickets oder zum Aktualisieren von Statusseiten
Memory und Zustandsverwaltung zur Nachverfolgung des Incident Fortschritts (versuchte Schritte, aktuelle Hypothese, usw.)
Agenten werden über eine KI-Middleware koordiniert, die Alarme an den richtigen Agenten weiterleitet und die Interaktionen steuert. Ziel ist es, dass beim Auslösen eines Alarms der zuständige Team-Agent mit den erforderlichen Tools aktiviert wird – ähnlich wie ein On-Call-Engineer, der mit einem vollständigen Runbook alarmiert wird.
Sichere Integration und Kontext Anreicherung
Ein kritischer Teil der Architektur ist der Fluss der Betriebsdaten zum Agenten. Wenn ein Alarm ausgelöst wird, startet die Incident-Management-Plattform zwei parallele Aktionen: Sie benachrichtigt die Person im Bereitschaftsdienst (wie üblich) und triggert den KI-Agenten.
Ausgehend von diesem Minimalkontext erstellt der Agent einen Plan, welche Tools er ausführt, um den Alarm einzuordnen. Er zieht Logs zum Incident-Zeitraum, aktuelle Metriktrends sowie jüngste Deployments oder Konfigurationsänderungen heran. Jeder Agent erhält nur Daten aus seinem Scope, wodurch die Isolation zwischen Teams gewahrt bleibt.
Tools wie Observability APIs, CI/CD-Pipelines und Cloud-Infrastruktur werden über Service Accounts mit minimal erforderlichen Rechten angebunden.
Ein Agent kann zum Beispiel einen Lesezugriff auf Metriken und Logs haben sowie begrenzten Schreibzugriff für bestimmte Aktionen (wie die Berechtigung seinen Service neu zu starten, aber ohne Datenbanken zu ändern, sofern dies nicht ausdrücklich freigegeben ist).
Diese Eindämmung verhindert, dass eine KI domänenübergreifend Schaden verursacht oder sensible Daten sieht, die sie nicht sehen sollte. Bei jedem Aufruf externer Systeme durch einen Agenten kommen starke Authentifizierungs- und Autorisierungsmechanismen zum Einsatz, sodass Agent-Aktionen wie die eines menschlichen Engineers protokolliert werden.
Orchestrierung und Steuerungseben
Im Kern sitzt die Orchestrierungsebene, die zentrale Steuereinheit für die Aktivitäten der KI-Agenten. Diese Ebene ist verantwortlich für
- Modellauswahl,
- Prompterstellung,
- Toolrouting,
- und die Durchsetung von Richtlinien.
Sie kann dynamisch entscheiden, welches LLM für eine Aufgabe verwendet wird (Abwägung zwischen Geschwindigkeit und Komplexität, z. B. ein kleineres Modell für schnelles Pattern Matching, ein größeres für komplexes Reasoning). Der Controller stellt außerdem Konsistenz und Performance über alle Agenten hinweg sicher und dient bei Bedarf als zentraler Knoten für die Koordination mehrerer Agenten.
Die Orchestrierungsebene baut Leitplanken, Regeln und Sicherheitsprüfungen um Agentenaktionen herum ein. Dazu gehören:
- Destruktive Aktionen blockieren (z. B. Datenlöschung, massenweises Herunterfahren), sofern keine menschliche Freigabe vorliegt.
- Agenten anhalten, die anomales oder repetitives Verhalten zeigen, um „Looping“ zu verhindern.
- Menschliche Freigabe für risikoreiche Schritte verlangen, etwa Änderungen in Produktion.
Diese Sicherungen stellen sicher, dass mit wachsender Autonomie die Sicherheit nicht leidet. Agenten bleiben leistungsfähig, jedoch stets innerhalb klar definierter Grenzen.
Observability and Feedback-Mechanismen
So wie wir Services überwachen, müssen wir auch die KI-Agenten überwachen. Die Architektur umfasst Logging und Observability für jede Entscheidung und Aktion eines Agenten. Alle Prompts und Antworten können aufgezeichnet werden (mit sensiblem Umgang mit Daten), um Audits und Debugging des KI-Verhaltens zu ermöglichen. Telemetrie kann Antwortzeiten, Confidence Scores, referenzierte Dokumente und die Ergebnisse von Aktionen (Erfolg/Fehlschlag) erfassen. Diese Daten fließen in einen Feedback-Kreislauf für kontinuierliche Verbesserung.
Wenn beispielsweise ein Agent eine falsche Annahme getroffen hat, können Engineers den Trace analysieren und Prompts verfeinern oder fehlendes Wissen ergänzen, um Wiederholungen zu vermeiden.
Zusammengenommen umfasst die Referenzarchitektur für agentic Incident-Management:
- Spezialisierte KI-Agenten, eingebunden in den Incident-Flow
- Eine sichere Kontext- und Integrationsschicht, die Daten liefert
- Eine Control-Schicht, die Betrieb steuert und Sicherheit durchsetzt
- Monitoring, das Performance nachverfolgt und verbessert
Diese Architektur startet mit Humans-in-the-Loop (Vorschläge, Freigaben) und erlaubt schrittweise mehr autonome Aktionen, sobald das Vertrauen wächst. Als Nächstes zeigen wir, wie dies in der Praxis je nach Autonomiestufe aussieht.
Praxisbeispiele: Autonomie-level L1–L3 im Einsatz
Um die Autonomiestufen greifbar zu machen, zeigen wir Szenarien, wie ein KI-Agent Incidents mit zunehmender Eigenständigkeit behandelt.
LevelStufe
Praktische Umsetzung
Beispiel
L1 - Beratung
Der Agent liefert ein RCA-Panel mit zentralen Ergebnissen, empfohlenen Maßnahmen und Entwürfen für die Kommunikation. Sie prüfen selbst und entscheiden.
KI postet in Slack: „Payment Service wurde in der letzten Stunde 3 Mal per OOM-Kill beendet. Vorschlag: auf v3.2.1 zurücksetzen (Rollback).“
→ Du erledigt weiterhin alles selbst, aber die Diagnose dauert 5 statt 45 Minuten.
L2 - Ausführung mit Freigabe
Du gibst die Ausführung im Chat oder in der Konsole frei. Der Agent führt das Runbook aus, prüft den Erfolg und schließt den Incident nach Lösung.
The human approves execution inline (chat or console). The agent runs a runbook, verifies success, closes the incident if resolved.
K8s memory leak: Der Agent schlägt vor, das Speicherlimit zu erhöhen → der Incident Commander (IC) gibt frei → der Agent wendet den Patch an.
L3 - Abgesicherte Autonomy
Der Agent führt vorab freigegebene, risikoarme Runbooks automatisch aus, mit Wirkradius Prüfungen und der Option zum Rollback. Bei unerwarteten Ergebnissen eskaliert der Agent.
Nach einem OOM-Kill startet der Agent einen zustandslosen Service automatisch neu. Wird der Service nicht gesund, setzt er die Änderung zurück und eskaliert.
Autonomie-Level 1: KI-unterstützte Reaktion (Co-Pilot Modus)
Szenario: Ein Alarm meldet hohe Speichernutzung auf Service A. In einem L1-Setup sammelt der KI-Agent für Service A sofort Kontext: Er zieht die letzten 15 Minuten Logs mit häufiger Garbage Collection und Fehlern, die auf einen OutOfMemoryError hinweisen, und notiert, dass vor 1 Stunde ein Deployment von Service A stattfand. Der Agent gleicht die Wissensbasis ab und findet einen Runbook-Eintrag zu Memory Leaks in einer jüngeren Version.
Auf dieser Stufe handelt der Agent nicht direkt, sondern agiert als Co-Pilot für die Bereitschaft. Er postet eine Analyse in den Incident-Chat:
„Wahrscheinliche Ursache: Memory Leak in Version 5.2, deployt um 12:00 UTC. Heap-Nutzung stieg bis zum OOM. Empfohlene Maßnahme: Service A neu starten, um Speicher zu leeren, und auf Version 5.1 zurücksetzen (Rollback), die dieses Leak nicht zeigt. Belege: Log-Auszüge [verlinkt], jüngstes Deployment [ID].“
Die Person im Bereitschaftsdienst erhält diese Informationen in Sekunden, statt 30 Minuten mit dem manuellen Sammeln von Logs und dem Rekonstruieren der Timeline zu verbringen. Mit diesen Informationen validiert der Engineer schnell und führt anschließend Neustart und Rollback des Services durch. Der Agent unterstützt auf Anfrage, indem er die genauen Befehle oder Schritte auflistet, z. B. Kubernetes Rollout Befehle.
Schlüsseleigenschaften von L1: Die KI liefert Einsichten und Optionen, Entscheidungen und Ausführung bleiben beim Menschen. Die Aktionen des Agenten sind nur lesend und beratend. Dies ist der Standardmodus, mit dem viele Organisationen starten, da er wenig Risiko birgt; der Agent kann nichts versehentlich beschädigen, weil er ohne Freigabe nichts ändert. Er beschleunigt vor allem die Diagnose: Logs, Metriken und bekannte Issues werden deutlich schneller analysiert, als es eine Person könnte. Der Agent kann auch vorschlagen, welche Fachperson einzubinden ist oder welches frühere Incident ähnlich ist. Alle Ausgaben sind für das Team transparent, und Engineers behandeln die Vorschläge wie die eines sehr versierten Teammitglieds. Ist eine Empfehlung falsch oder irrelevant, ignoriert das Team sie und setzt die eigene Untersuchung fort und gibt später Feedback, damit das Modell lernt.
Bei L1 liegt der Fokus darauf, Vertrauen in die KI-Ergebnisse aufzubauen und sie nahtlos in die Incident-Kommunikationskanäle zu integrieren.
Autonomie-Level 2: Menschlich-gesteuerte Automatisierung (Teilautomatisierung)
Szenario: Angenommen, eine Read Replica von Datenbank X ist offline. In einem L2-Setup hat der Database Ops Agent die Berechtigung, einen abgegrenzten Satz von Maßnahmen auszuführen – mit menschlicher Freigabe.
Beim Erkennen der offline Replica diagnostiziert der Agent zunächst das Problem: Er prüft die Erreichbarkeit der Replica (Ping fehlgeschlagen), findet in den Logs, dass die Instanz vom Kernel wegen OOM beendet wurde, und sieht, dass dies bei ähnlichen Instanzen bereits vorkam.
Die bekannte Abhilfe (laut Runbook und früheren Incidents) ist, den Datenbankdienst neu zu starten und, falls das fehlschlägt, eine neue Replica zu promoten.
In Stufe L2 darf der Agent diese Routine-Maßnahme mit Freigabe ausführen, weil sie risikoarm und reversibel ist und im erlaubten Runbook liegt. Nach Freigabe startet der Agent die Datenbankinstanz neu und überwacht den Zustand einige Minuten lang. Gelingt der Neustart und die Replica kommt wieder online, aktualisiert der Agent Ticket oder Chat: „DB-Replica-Ausfall erkannt und Service automatisch neu gestartet. Replica ist wieder online und synchronisiert. Keine weiteren Maßnahmen nötig.“
Schlüsseleigenschaften von L2: Der KI-Agent kann bestimmte Fixes vorschlagen und sie nach menschlicher Freigabe ausführen. Typischerweise sind das geprüfte, als sicher eingestufte Automatisierungen. Beispiele: Applikationscache leeren, eine festhängende Instanz neu starten, einen Service bei hoher Last skalieren oder Diagnosepakete sammeln (z. B. Thread-Dumps erstellen).
Der Agent agiert als First Responder und übernimmt einfache Aufgaben. Menschen überwachen indirekt, prüfen Logs und erhalten Benachrichtigungen über die durchgeführten Schritte. Diese Stufe reduziert die MTTR spürbar, da viele Incidents in wenigen Minuten mit minimaler menschlicher Beteiligung automatisch behoben werden können.
Autonomie-Level 3: Bedingte Vollautomatisierung (proaktive Behebung)
Szenario: Eine kritische Webanwendung hat ein Memory Leak und stürzt in Produktion ab. In einem L3-Setup diagnostiziert und behebt der Application Service Agent das Problem nicht nur, sondern handelt auch vorausschauend. Er überwacht, beispielsweise, Speichermuster mit einem Anomaliemodell und erkennt einen Trend, der auf ein wahrscheinliches Memory Leak in der neuen, am selben Tag bereitgestellten Version.
Bevor Kund:innen etwas merken, startet der Agent ein Canary Rollback: Er lenkt einen kleinen Anteil des Traffics zurück auf die vorherige Version, um die Hypothese zu prüfen. Sinken die Fehlerraten auf der alten Version, setzt der Agent den gesamten Service automatisch auf die stabile Version zurück. Außerdem markiert er die neue Version im Deployment System als problematisch, um weitere Rollouts zu verhindern.
All das geschieht ohne menschliches Eingreifen in Echtzeit. Das erste Signal für Menschen ist ein automatisch erstellter Incident Report: „Service Y hatte ein Memory Leak in Version 3.4, deployt um 14:00. Der Agent hat um 15:10 auf Version 3.3 zurückgesetzt (Rollback), nachdem er steigende Speichernutzung erkannt hatte, und so einen drohenden Absturz verhindert. Auswirkungen wurden proaktiv begrenzt.“ Zusätzlich erstellt der Agent ein Ticket für das Entwicklungsteam mit den gesammelten Daten zur Analyse (z. B. Heap Dumps).
Schlüsseleigenschaften von L3: Der KI-Agent kann für bestimmte Incident-Klassen den gesamten Ablauf autonom übernehmen – von Erkennung über Behebung bis zur Post-Incident Dokumentation. Voraussetzung ist ausreichend Vertrauen in die Genauigkeit des Agenten und ein klar abgegrenzter Scope, sodass der Agent „weiß, was er nicht weiß“. Bei bekannten Fehlermustern braucht er keine menschliche Unterstützung. Er geht zudem präventiv vor und erkennt Probleme, bevor sie sich zu Ausfällen auswachsen. Menschen setzen weiterhin die Grenzen: Der Agent arbeitet typischerweise mit einer Allowlist von Szenarien oder einer Konfidenzschwelle. Fällt etwas außerhalb davon (z. B. nur 50 % Vertrauen oder ein sehr seltener Incident), fällt er auf L1 oder L2 zurück (informiert oder holt eine Freigabe ein).
Im Kern ist L3 bedingte Autonomie: volle Freiheit zur Behebung, wenn die Kriterien erfüllt sind, und sicherer Rückfall auf menschlichen Input bei hoher Unsicherheit. In dieser Stufe erzielen Organisationen maximale Vorteile bei Uptime und Effizienz, da viele Incidents schneller gelöst werden, als ein Mensch reagieren könnte. Der Fokus des Teams verlagert sich darauf, das Wissen der KI zu validieren und zu erweitern sowie Edge Cases zu bearbeiten, die die KI nicht abdeckt.
Jenseits von L3 übernehmen Agenten der Stufen L4 - L5 neue Incidents mit kreativen Lösungswegen und koordinieren domänenübergreifend ohne Runbook. Diese Vision vertiefen wir im strategischen Ausblick.
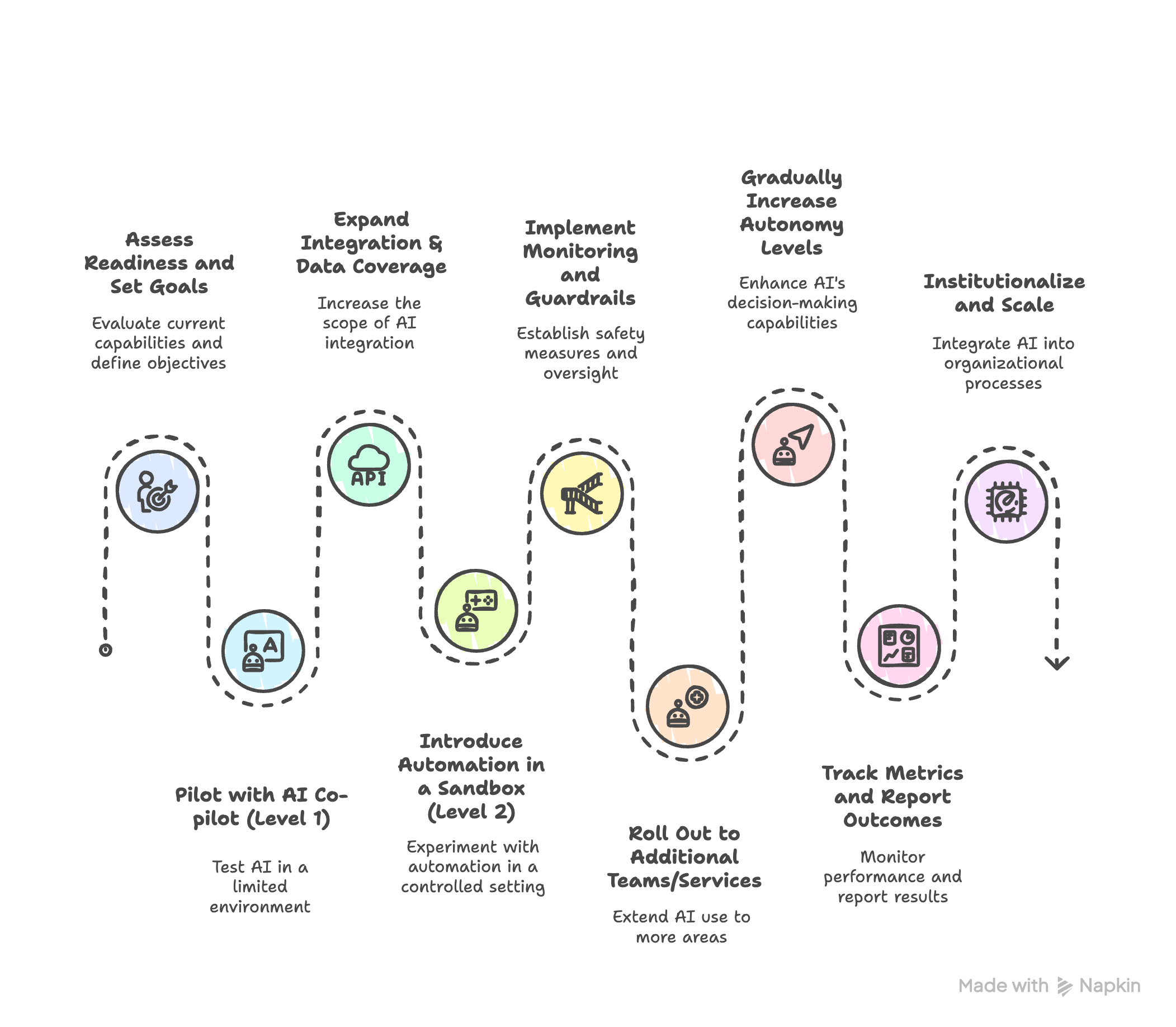
Implementierungsplan
Die Einführung von agentic Incident-Management gelingt am besten in Phasen. Hier ist ein praktischer Umsetzungsplan, um KI-Agenten Schritt für Schritt sicher und effektiv einzuführen:
- Prüfen Sie die Ausgangslage und legen Sie Ziele fest
- Starten Sie einen Pilot mit KI-Co-Pilot (Level 1) in engem Scope
- Erweitern Sie Integration und Datenabdeckung
- Führen Sie Automatisierung in einer Testumgebung ein (Level 2 Tests)
- Implementieren Sie eine Orchestrierungsebene und Sicherheitsüberprüfungen
- Führen Sie die Lösung in weiteren Teams und Services ein
- Erhöhen Sie die Autonomiestufen schrittweise
- Verfolgen Sie Metriken und berichten Sie Ergebnisse
- Institutionalisieren und skalieren Sie weiter
1. Prüfen Sie die Ausgangslage und legen Sie Ihre Ziele fest
- Reife bewerten: Prüfe deine aktuellen Incident Response Prozess und identifizieren Pain Points (z. B. hohe MTTR, Alert Fatigue, häufige Anrufe außerhalb der Supportzeiten).
- Prüfe die Datenlandschaft: Stelle sicher, dass Telemetrie, Logs und Knowledge Repositories verfügbar sind, die ein KI-Agent benötigt.
- Definiere Erfolgskriterien: Setze messbare Ziele (z. B. „MTTR in 12 Monaten um 30 % senken“ oder „20 % der Incidents auf L2 automatisch beheben“).
- Sichere das Buy-in: Verdeutliche das Business Value – gesparte Engineer-Zeit, höhere Uptime, geringere Kosten.
2. Pilot mit Co-pilot (Level 1) in einem kleinen Scope:
- Scope wählen: Wähle einen risikoarmen Bereich mit hohem Nutzen, z. B. einen einzelnen Service oder einen häufigen Incident-Typ (etwa „Disk full“-Alarme, HTTP 500 spikes).
- Daten vorbereiten: Sammele frühere Incidents, Logs und Runbooks für diesen Service.
- Zugriff begrenzen: Lasse den Agenten zunächst nur lesend arbeiten, um Sicherheit zu gewährleisten.
- Team schulen: Zeige Engineers im Bereitschaftsdienst, wie sie die Analyse des Agenten während Incidents nutzen.
- Simulationen durchführen: Führe Übungen durch, um Reaktionen zu testen und Prompts oder Wissen zu verfeinern.
- Beitrag validieren: Prüfe, ob der Agent nützliche Einsichten liefert (z. B. Hinweise auf die Ursache). Sammele Feedback zu Genauigkeit und Relevanz, um Vertrauen aufzubauen.
3. Integration und Datenabdeckung erweitern:
- Wissensbasis ausbauen: Ergänze zusätzliche Dokumentation und verknüpfen den Agenten mit Enterprise-Wikis bzw. Wissenssystemen.
- Datenquellen ergänzen: Binde Observability- und Logging-Tools, CI/CD-Ereignisse, Konfigurationsdaten sowie Ticket-Historien an. Mehr Kontext erhöht die Genauigkeit.
- Datenzufuhr aufbauen: Führe eine Ebene zur Zusammenstellung von Kontext ein (z. B. über das MCP-Protokoll), um den Agenten strukturiert mit Echtzeitdaten zu versorgen.
- Datenqualität und Datenschutz sicherstellen: Anonymisiere oder pseudonymisiere sensible Kundendaten, bevor sie die KI erreichen, und sichern Sie alle Verbindungen.
Diese Phase verwandelt den Agenten in einen gut-informiertes "Hirn" mit Zugang zu den notwendige Wissen und Daten.
4. Führen Sie Automatisierung in einer Testumgebung ein (Level 2 Tests):
- Definiere Sichere Aktionen: identifiziere risikoarme Tasks (z. B. Dienst neu starten, Queue leeren, Feature Flag umschalten).
- In Staging testen: simuliere bekannte Issues in einer Testumgebung und lass den Agenten Fixes versuchen, um sein Verhalten zu verifizieren.
- Freigabe-Workflows entwerfen: entscheide, welche Aktionen automatisch ausgeführt werden und welche eine Bereitschaftsbestätigung brauchen.
- Feature Flags/Config-Toggles nutzen: steuere den Rollout autonomer Ausführung für ausgewählte Aktionen.
- Klein in Produktion starten: aktiviere eine automatisierte Aktion unter engem Monitoring und erweitere schrittweise.
5. Implementieren Sie eine Orchestrierungsebene und Sicherheitsüberprüfungen:
- Audit-Logs führen: protokolliere alles, was der Agent tut oder empfiehlt, für Post-Incident-Analyse und Vertrauen der Stakeholder.
- Fail-safes etablieren: stelle sicher, dass Incidents Menschen erreichen, wenn die Behebung stockt.
- Rollback planen: definiere Recovery-Schritte, falls die Änderung des Agenten nicht wirkt; idealerweise führt der Agent ein Auto-Rollback durch, wenn keine Verbesserung erkennbar ist.
6. Führen Sie die Lösung in weiteren Teams und Services ein:
- Scope erweitern: klone das Setup für neue Teams oder Services mit eigenen Datenfeeds und Knowledge.
- Sinnvoll priorisieren: fokussiere Bereiche mit hoher Alarmflut oder sicheren Automationschancen.
- Onboarding unterstützen: biete Training, Doku und Opt-in an. Nutze Success Stories, um Momentum aufzubauen.
- Center of Excellence: lass ein Pilotteam andere Teams anleiten.
- Konsistenz und Anpassung balancieren: gemeinsame Security und Interfaces beibehalten, aber domänenspezifisches Wissen pro Team erlauben.
7. Erhöhen Sie die Autonomiestufen schrittweise:
- Schritt für Schritt vorgehen: von Vorschlägen (L1) zu automatisierten Aktionen (L2/L3) wechseln, sobald die Genauigkeit belegt ist.
- Datengetriebene Schwellen: Autonomie formalisieren, wenn wiederholte menschliche Freigaben die Lösung des Agenten validieren.
- Review und Iteration: Incidents regelmäßig analysieren, um Scope und Confidence des Agenten zu erweitern.
- Freigaben über die Zeit reduzieren: mehr Verantwortung an die KI übergeben, wenn die Zuverlässigkeit wächst.
8. Verfolgen Sie Metriken und berichten Sie Ergebnisse
- Quantitative Kennzahlen: MTTR-Reduktion, weniger After-hours-Pages, höhere Auto-Resolution-Rates.
- Qualitatives Feedback: Stresslevel der Engineers, Konsistenz und Vertrauen in den Agenten erfassen.
- Datenbasiert verfeinern: Schwachstellen mit mehr Beispielen oder engeren Integrationen verbessern.
- Erfolge kommunizieren: Verbesserungen teilen, um Buy-in zu halten.
9. Institutionalisieren und skalieren Sie weiter
- Prozesse aktualisieren: Agent in Runbooks, On-call-Training und Postmortems verankern.
- Ownership definieren: Verantwortung für Knowledge Bases, Prompts und Modell-Updates zuweisen (ggf. neue AI-Operations-Rolle).
- Modelle pflegen: Retraining und Prompt-Weiterentwicklung bei Systemänderungen einplanen.
- Skalierung optimieren: Performance managen, wenn mehrere Agenten parallel laufen.
- KI in den Ops normalisieren: Agenten wie Teammitglieder behandeln und kontinuierlich verbessern, während die Technologie voranschreitet.
Halte über alle Schritte hinweg eine Feedback-Schleife mit den Endnutzern (den On-call Engineers und Team Leads) aufrecht.
Ihr Buy-in und Vertrauen sind entscheidend.
Geh offen auf Bedenken ein – z. B. auf Sorgen über Jobauswirkungen oder Kontrollverlust – und betone, dass die KI ein Werkzeug ist, das ihr Leben erleichtert, nicht der Ersatz für ihre Expertise
Responder Agenten ersetzen keine Menschen; sie holen sich ihren REM-Schlaf zurück. Schließlich wurde niemand eingestellt, um in Vollzeit on call zu sein.Beziehe sie in die Festlegung der Richtlinien ein, was der Agent tun darf.
Dieser Plan, ermöglicht, die sorgfältig umgesetzt, einen sicheren Übergang vom manuellen Incident Management zu einem KI-gestützten und schließlich weitgehend autonomen Paradigma.
Kernmetriken und Erfolgsindikatoren
Die Wirkungen von agentenbasierten Incident-Management zu messen hilft, die Effektivität zu bewerten und weitere Investitionen zu rechtfertigen. Wichtige Metriken und Indikatoren sind:
Mean time to resolution (MTTR)
Die durchschnittliche Zeit vom Incident-Start bis zur Behebung. Ein zentrales Ziel von agentenbasiertem Management ist, diese deutlich zu senken. Tracke die MTTR vor und nach dem Einsatz von KI-Funktionen. Viele Teams sehen Verbesserungen, weil der Agent die Diagnose beschleunigt und teils Fixes selbst ausführt; beispielsweise kann die MTTR bei Incidents mit Unterstützung eines Agenten von 1 Stunde auf 30 Minuten sinken.
Diagnose-Zeit
Eine Detailansicht auf die MTTR mit Fokus auf die Analysephase. Tracke, wie lange es dauert, die Root Cause eines Incidents zu identifizieren. Liefert der Agent schnell eine Hypothese oder stützende Evidenz, sollte sich dieser Wert um eine Größenordnung verkürzen. Du kannst die Zeit vom Incident-Start bis zu dem Zeitpunkt messen, an dem der On-call die Root Cause als gefunden erklärt. Verbesserungen hier belegen den Wert des Agenten, Datenrauschen schneller zu durchdringen als die manuelle Suche.
Autonome Lösungsrate
Der Prozentsatz der Incidents, die der KI-Agent ohne menschliches Eingreifen löst. Das ist ein direkter Indikator für den erreichten Autonomiegrad. In frühen Phasen kann dieser bei 0 % liegen (Agent gibt nur Empfehlungen). Mit L2–L3-Autonomie trackst du, welcher Anteil der Incidents durch Aktionen des Agenten geschlossen wird. Du kannst Ziele setzen, z. B. 10 % auto-resolved in den ersten 6 Monaten, 30 % nach einem Jahr, zunächst fokussiert auf Low-Severity- oder repetitive Incidents.
Akzeptanzrate für Vorschläge
Wenn der Agent auf L1 arbeitet (oder bei L2 mit menschlicher Freigabe), tracke, wie oft das Team die Empfehlungen befolgt. Wenn der Agent eine Remediation vorschlägt und der On-call zustimmt und sie ausführt, ist das ein erfolgreicher Vorschlag. Eine hohe Akzeptanzrate (z. B. „80 % der Agenten-Vorschläge in Q1 wurden genutzt“) bedeutet, dass die Ratschläge konsistent gut und vertrauenswürdig sind. Eine niedrige Rate kann auf Genauigkeitsprobleme hindeuten und darauf, Modell oder Daten zu verbessern.
Uptime / SLA Impact
Letztlich sollte besseres Incident-Management die Service-Verfügbarkeit verbessern. Tracke die SLA/SLO-Einhaltung – z. B. den Prozentsatz der Incidents, die innerhalb der SLA-Ziele gelöst wurden. Wenn agentenbasiertes Management wirkt, sollten mehr Incidents innerhalb akzeptabler Zeitfenster bleiben.Zusätzlich sollten ungeplante Downtime-Stunden pro Quartal getrackt werden, denn eine Reduktion ist ein starker Business-Indikator – auch wenn viele Faktoren darauf wirken, ist KI nur einer davon.
On-call Last und Zfriedenheit der Engineers
Tracke menschenzentrierte Ergebnisse wie geleistete On-call-Stunden und subjektive Stresslevel. Befrage deine Engineers, ob die KI-Tools Incidents leichter handhabbar machen. Ein Rückgang von Burnout oder eine höhere On-call-Zufriedenheit (per regelmäßigen Umfragen) ist ein wertvoller Erfolgsindikator. Tracke außerdem, ob die gesamten Engineering-Stunden pro Incident (kumuliert) sinken – z. B. wenn ein größerer Incident früher 5 Engineers × 2 Stunden = 10 Stunden brauchte und dank Agent nur noch 2 Engineers × 1 Stunde = 2 Stunden, ist das ein großer Produktivitätsgewinn.
Feedback- und Lernschleifen-Metriken
Wenn du ein Feedback-System hast (z. B. Daumen hoch/runter bei Agent-Antworten oder ein Scoring für Empfehlungen), tracke diese Metriken.
Eine hohe Quote positiven Feedbacks bedeutet, dass die Ausgaben des Agenten generell gut sind. Tracke außerdem, wie viele Verbesserungen oder Modell-Updates durch Feedback ausgelöst wurden – so stellst du sicher, dass kontinuierliches Lernen stattfindet.
Um Fortschritte zu verfolgen, stelle sicher, dass die richtige Instrumentierung vorhanden ist.Die meisten Incident-Management-Tools können Erkennungs-, Bestätigungs- und Behebungszeiten protokollieren, aber du musst sie ggf. erweitern, um zu kennzeichnen, welche Incidents KI involvierten. Manche Teams bauen sogar eigene Dashboards für die Agenten-Performance.
Das Ziel ist nicht nur, den Nutzen zu belegen, sondern Schwächen zu erkennen. Wenn die MTTR nicht sinkt: Tritt die Verlangsamung während der Ausführung auf? Das kann darauf hindeuten, dass der Agent mehr Autonomie braucht, um Fixes anzuwenden statt sie nur vorzuschlagen. Wenn False Positives zunehmen, begrenze den Scope des Agenten oder verfeinere seine Algorithmen, bevor du skalierst. Datengetriebene Verfeinerung hält dein agentenbasiertes Incident-Management-Programm auf Kurs.
Beschaffungscheckliste für KI Incident Management Lösungen
Für Organisationen, die eine externe, KI-gestützte Incident-Management-Plattform (oder ähnliches Tooling) kaufen oder bewerten möchten, ist es wichtig, die richtigen Fragen zu stellen.Unten findest du eine Käufer-Checkliste mit Kriterien, um sicherzustellen, dass die Lösung Enterprise-Anforderungen erfüllt
Integration bestehender Tools
Verbindet sich die Lösung nativ mit euren Monitoring-Systemen (Datadog, CloudWatch, Prometheus etc.), Logging-Plattformen (ELK, Splunk) und ITSM/Ticketing (ServiceNow, Jira)? Nahtlose Integration ist entscheidend, damit die KI Zugriff auf alle nötigen Daten hat und in euren Workflows handeln kann. Prüfe Out-of-the-box-Connectoren oder APIs und den Aufwand, um individuelle In-house-Systeme anzubinden.
Datenschutz und Datenhoheit
Wie geht der Anbieter mit Daten um? Stelle sicher, dass eure Incident-Daten nicht für das Training von Modellen für andere Kunden genutzt werden (seriöse Anbieter verzichten standardmäßig auf Datenteilung). Prüfe, wo Daten verarbeitet und gespeichert werden – das muss zu euren Compliance-Vorgaben passen (z. B. EU-Rechenzentren für GDPR). Wenn Cloud-LLMs genutzt werden: Setzt der Anbieter Verschlüsselung oder Mandantenisolation ein, um eure Informationen zu schützen? Frage nach dokumentierten Datenschutzmaßnahmen und relevanten Zertifizierungen (ISO 27001, SOC 2 etc.).
Sicherheit und Zugriffskontrolle
Wie sichert die Plattform die Aktionen des KI-Agents ab? Achte auf rollenbasierte Zugriffskontrolle (RBAC): Du solltest Berechtigungen festlegen können, was der Agent in jeder Umgebung sehen oder tun darf. Unterstützt die Lösung die Integration mit eurem Identity Provider oder SSO zur Zugriffsteuerung? Frage auch nach Audit-Logging – jede Aktion des Agents sollte protokolliert und nachvollziehbar sein. Der Anbieter sollte eine Möglichkeit bieten, diese Logs für euer Security-Team zu prüfen und zu exportieren. Bewerte, ob die Architektur dem Least-Privilege-Prinzip folgt (z. B. laufen Agent-Module unter eingeschränkten Accounts) und ob es Schutzmechanismen gegen unautorisierte Kommandos gibt
Autonome Konfiguration
Kannst du den Autonomiegrad der KI konfigurieren? Eine gute Lösung erlaubt den Start im Empfehlungsmodus und das schrittweise Aktivieren automatisierter Aktionen entsprechend eurer Komfortzone. Prüfe granulare Controls – etwa Policys wie „automatischer Neustart für Service A erlauben, aber für Datenbank-Failover Freigabe verlangen“. Das System sollte autonome Fähigkeiten leicht toggelbar machen (z. B. vollständige Automatisierung während Freeze oder kritischen Phasen deaktivieren).
Transparenz und Erklärbarkeit
Liefert die KI Begründungen zu ihren Entscheidungen? Für Vertrauen darf das Tool keine Black Box sein. Bitte den Anbieter in der Evaluation zu zeigen, wie eine Incident-Analyse präsentiert wird – idealerweise kommen die Outputs des Agents mit Erklärungen wie „Aktion X empfohlen, weil Metrik Y den Schwellenwert überschritten hat und Log Z Fehler Q zeigt“. Falls die Plattform ein UI hat, sollte es Evidenz oder Referenzen (inkl. Links zu Quelldaten) anzeigen, die die Vorschläge stützen. So können Engineers die KI validieren und Vertrauen aufbauen.
Leistung und Latenz
Incident Response ist zeitkritisch. Frage nach typischer und Worst-Case-Latenz, bis der KI-Agent analysiert und reagiert. Wenn ein Alarm triggert: Kommen Empfehlungen in Sekunden oder dauert es Minuten? Kann das System Spikes bewältigen (z. B. mehrere Incidents gleichzeitig)? Suche nach Benchmarks oder Customer References zur Geschwindigkeit und Skalierbarkeit. Wenn große Modelle eingesetzt werden, nutzen sie Techniken für schnelle Antworten (z. B. kleinere Modelle für einfache Tasks)? Ein Hands-on-Trial in eurer Umgebung ist sinnvoll, um das zu messen.
Modell- und Funktionsaktualisierungen
KI entwickelt sich schnell. Wie aktualisiert der Anbieter zugrunde liegende Modelle oder fügt neue Fähigkeiten hinzu? Ist das System modular genug, um neue LLMs oder Verbesserungen ohne Betriebsstörung einzubinden? Ideal sind regelmäßige Updates oder die Wahlmöglichkeit, wann ihr Modelle upgradet. Frage, ob ihr ein eigenes Modell (BYOM) einbringen oder bei Bedarf auf euren Daten feinjustieren könnt. Die Roadmap ist aussagekräftig – ein aktiv investierender Anbieter hält euch vorn.
Anpassbarkeit und Schulung
Jede Umgebung ist einzigartig. Die Lösung sollte Anpassungen erlauben, z. B. eure eigene Knowledge Base (Docs, Runbooks) einbinden und Regeln maßschneidern. Frage, ob ihr das „Wissen“ der KI editieren/erweitern könnt – etwa ein internes Wiki hochladen oder durch Feedback korrigieren, wenn sie falsch liegt. Manche Plattformen erlauben eigene Actions oder Skripte, die der Agent ausführen kann. Achtet darauf, dass dieser Prozess benutzerfreundlich ist und nicht für jede Kleinigkeit Professional Services erfordert. Je besser ihr das System auf euren Kontext tuned, desto wirksamer wird es.
Nachgewiesene Wirkung und Referenzen
Fordere Case Studies oder Referenzen ähnlicher Unternehmen an, die das Produkt nutzen. Frage gezielt nach messbaren Ergebnissen: „Company X hat P1-Incident-MTTR nach 6 Monaten um 40 % reduziert“ oder „Y % der Incidents werden jetzt vom Agent auto-resolved“. Auch wenn jede Umgebung anders ist, helfen konkrete Resultate, Anbieter-Aussagen zu validieren. Wenn möglich, führt ein Pilot/PoC in eurer Umgebung durch, um die Verbesserung an einem Teil der Incidents direkt zu messen. Bewertet anhand zentraler Metriken – zeigt das Tool im Trialzeitraum eine klare Verbesserung?
Support und Zuverlässigkeit
Da die Lösung Teil eurer Incident Response wird, muss sie selbst zuverlässig und gut unterstützt sein. Prüfe die SLAs des Anbieters (Uptime-Zusagen für die Cloud, Support-Reaktionszeiten etc.). Wenn beim Incident ein Problem mit dem KI-Agent auftritt – welchen Support gibt es? Achte auf 24/7-Supportoptionen oder einen dedizierten Customer Success Engineer, besonders zu Beginn des Rollouts. Auch die AI-Reife des Anbieters ist relevant – frage nach der Expertise des Teams (arbeiten AI-Researchers, SREs etc. daran) und nach der langfristigen Produktvision.
Kosten und Lizenzierung
Verstehe das Preismodell klar. Wird pro Incident, pro User, monatlich oder nach Ressourcenverbrauch abgerechnet (z. B. Tokens oder API-Calls für LLMs)? Schätze, wie das mit eurem Incident-Volumen skaliert. Achte auf kostspielige Überraschungen, wenn die KI viel Daten analysiert (manche rechnen nach ingestierten Daten oder Integrationen ab). Frage nach Limits (Anzahl Agents, Datenaufbewahrung etc.) je Preistier. Berücksichtige zusätzliche Infrastrukturkosten (z. B. bei Self-Hosting die Kosten für den Betrieb der Modelle). Idealerweise zeigt die Lösung einen klaren ROI – weniger Downtime oder eingesparte Arbeitszeit im Verhältnis zu den Kosten.
Diese Checkliste gibt dir eine strukturierte Methode, Anbieter zu bewerten, die KI-gestütztes Incident-Management versprechen. Sie hilft zu bestätigen, dass die Lösung zu deinem Tech-Stack, deinen Sicherheitsanforderungen und deinen Unternehmenszielen passt. Eine sorgfältige Bewertung im Vorfeld verhindert spätere, schmerzhafte Fehlentscheidungen.
Beachten Sie: KI einzuführen heißt nicht nur, ein Tool zu kaufen – es ist der Beginn einer Partnerschaft. Laufendes Tuning, Updates und Zusammenarbeit sind wichtig, daher solltest du das Engagement des Anbieters und den Fit zu eurer Arbeitsweise im Team mitbewerten.
Unten finden Sie eine Vorlage, mit der sich Anbieter vergleichen lassen:
Anbieter
Angebot A
Angebot B
Angebot C
Integration von bestehenden Tools
Datenschutz & Datenhoheit
Sicherheit & Zugriffskontrolle
Autonome Konfiguration
Transparenz & Erklärbarkeit
Leistung und Latenz
Modell- & Funktionsaktuali sierungen
Model and capability updates
Anpassung & Schulung
Nachgewiesene Wirkung & Referenzen
Support & Zuverlässigkeit
Kosten und Lizenzierung
Strategischer Zukunftsausblick
Mit der Weiterentwicklung des agentenbasierten Incident Managements zeichnen sich mehrere bahnbrechende Fortschritte ab. Diese werden in den nächsten fünf Jahren und darüber hinaus die Schnittstelle zwischen KI und Automatisierung einerseits und IT-Betrieb andererseits prägen:
- Code generierende und selbstreparierende Agenten
- Domänenübergreifende Zusammenarbeit und Zusammenarbeit mehrerer Agenten
- Erhöhte Autonomie bei verbesserter Sicherheit
- Domänenspezifische LLMs und Wissensdatenbanken
- Einheitliche Automatisierung in IT und Geschäftskontinuität
- Sich wandelnde Rolle des Menschen – vom Reagierenden zum Strategen
Code generierende und selbstrepariende Agenten
Zukünftige KI-Agenten werden wahrscheinlich über vordefinierte Runbooks hinausgehen und tatsächlich Code oder Skripte schreiben, um Probleme zu beheben. Wir sehen bereits LLMs, die sich mit der Generierung von Konfigurationsdateien, Patches oder Skripting-Aufgaben auskennen. Im Falle eines Vorfalls könnte ein Code generierender Agent einen Fehler identifizieren und eine Codeänderung zur Behebung vorschlagen, möglicherweise sogar die Korrektur implementieren und einen Pull-Request öffnen.
Ein KI-Agent, der beispielsweise einen Ausfall in einem E-Commerce-System erkennt, könnte autonom nicht nur IT-Korrekturen, sondern auch Geschäftsprozesse auslösen – wie z. B. das Anhalten einer Marketingkampagne (um die Auslastung zu reduzieren) oder das Vorentwerfen einer Kundenbenachrichtigung über die Dienstunterbrechung. Agenten könnten in Disaster-Recovery-Verfahren (Auslösen eines Failovers zu Backup-Rechenzentren) und sogar in das Facility Management bei Ausfällen vor Ort (z. B. Koordinierung eines Neustarts über IoT-Geräte) eingebunden werden.
Diese Vision selbstheilender Systeme bedeutet: Agenten starten nicht nur Dienste neu, sie verbessern die Software, um Wiederholungen zu verhindern. Organisationen sollten sich darauf vorbereiten, indem sie ihre Agenten in CI/CD-Pipelines und Testframeworks integrieren, sodass jeder KI-generierte Fix vor dem Deployment automatisch durch Tests validiert wird.
Domänenübergreifende Zusammenarbeit und Zusammenarbeit mehrerer Agenten
Derzeit sind Agenten häufig auf bestimmte Teams oder Funktionen beschränkt. In Zukunft wird es eine breitere Zusammenarbeit zwischen KI-Agenten über verschiedene Domänen hinweg geben (Anwendung, Netzwerk, Sicherheit usw.). Komplexe Vorfälle erstrecken sich oft über mehrere Bereiche – beispielsweise kann ein Ausfall gleichzeitig Anwendungsfehler, ein Problem mit dem Netzwerk-Routing und das Ablaufen eines Sicherheitszertifikats umfassen.
Heute kümmern sich mehrere menschliche Teams um solche Probleme, morgen könnten mehrere spezialisierte Agenten in Echtzeit koordiniert werden. Wir erwarten Architekturen, in denen Agenten über standardisierte Protokolle kommunizieren (ein „Internet der Agenten”-Konzept), Beobachtungen austauschen und Aufgaben aufteilen.
Beispielsweise erkennt ein Anwendungsagent eine Datenbankverzögerung, konsultiert einen Datenbankagenten, der eine langsame Abfrage findet, und signalisiert einem Cloud-Infrastrukturagenten, eine größere Instanz bereitzustellen – alles über automatisierte Verhandlungen. Diese domänenübergreifende Automatisierung ermöglicht es, Vorfälle aus einer systemweiten Perspektive und nicht aus isolierten Sichtweisen zu lösen. Um dies zu erreichen, sind Interoperabilitätsstandards und möglicherweise ein übergeordneter „Manager“-Agent erforderlich, der die Zusammenarbeit koordiniert. Dies bringt auch neue Herausforderungen hinsichtlich der Konsistenz (sicherstellen, dass sich die Agenten nicht gegenseitig ins Gehege kommen) und des Kommunikationsaufwands mit sich. Wenn dies jedoch richtig umgesetzt wird, bedeutet dies eine wirklich ganzheitliche Vorfallsbearbeitung – der gesamte Stack kann von der KI-Belegschaft optimiert und repariert werden.
Erhöhte Autonomie mit Sicherheitsverbesserungen
Da die Branche durch messbare Zuverlässigkeit Vertrauen in KI gewinnt, werden wir uns der vollständigen Autonomie (Stufen 4–5) annähern. Dies bedeutet, dass Agenten neue Situationen mit minimaler Aufsicht bewältigen können. Um dies zu erreichen, erwarten wir hohe Investitionen in Sicherheitsebenen rund um KI. Techniken wie eingeschränkte Bayes'sche Optimierung, formale Verifizierung von KI-Entscheidungen in kritischen Pfaden und Sandboxing-Ausführungen werden zum Standard werden.
Bevor ein Agent beispielsweise eine komplexe Datenbankmigration durchführt, um einen Vorfall zu beheben, könnte er eine Simulation des Ergebnisses in einer digitalen Zwillingsumgebung durchführen. Eine solche erweiterte Validierung kann grünes Licht für Maßnahmen geben, die wir heute niemals automatisieren würden. Darüber hinaus könnte sich die Echtzeitüberwachung der „Denkprozesse” von Agenten weiterentwickeln – ähnlich wie selbstfahrende Autos ständig ihre neuronalen Netze auf Anomalien überprüfen. Möglicherweise werden externe „Watchdog“-KI-Komponenten zum Einsatz kommen, die den primären Agenten beobachten und eingreifen können, wenn er sich unerwartet verhält (KI überwacht KI).
All dies wird dazu beitragen, die Obergrenze der Autonomie sicher anzuheben, sodass Agenten mehr ohne menschliches Eingreifen bewältigen können, jedoch mit Sicherheitsvorkehrungen, die der Zuverlässigkeit des menschlichen Urteilsvermögens entsprechen oder diese sogar übertreffen.
Domänenspezifische LLMs und Wissensdatenbanken
Die nächste Generation von Incident-Management-Agenten wird von spezialisierteren LLMs profitieren. Anstelle eines allgemeinen Modells, das versucht, alles zu wissen, werden wir Modelle haben, die speziell auf IT-Betrieb, Netzwerke oder bestimmte Anbietertechnologien abgestimmt sind.
Diese spezialisierten Modelle werden technische Protokolle und Fehlermeldungen noch besser verstehen, da sie auf einem umfangreichen Korpus von IT-Daten (Tickets, Handbücher, Foren) trainiert wurden. Unternehmen könnten sogar ihre eigenen Modelle anhand der Daten ihrer Umgebung trainieren und so eine interne „KI-SRE“ schaffen, die ihre Systeme genau kennt. Daneben werden wir eine reichhaltigere Wissensintegration erleben – Agenten werden nicht nur statische Runbooks heranziehen, sondern auch Echtzeit-Dokumentationen (z. B. durch Parsen von Code-Repositorys oder Konfigurationsdateien, um den aktuellen Status zu verstehen).
Agenten werden auch besser darin werden, aus jedem Vorfall zu lernen. Heute protokollieren wir Lehren in Nachbesprechungen, aber zukünftige Agenten könnten ihre Wissensbasis automatisch aktualisieren, wenn eine neue Lösung oder Ursache entdeckt wird, und so mit jedem gelösten Vorfall wirklich intelligenter werden.
Einheitliche Automatisierung in den Bereichen IT und Geschäftskontinuität
In Zukunft könnte sich der Anwendungsbereich von Agenten über reine technische Vorfälle hinaus auf Geschäftskontinuität und Ausfallsicherheit erstrecken
Beispielsweise könnte ein KI-Agent, der einen Ausfall in einem E-Commerce-System erkennt, nicht nur IT-Korrekturen, sondern auch Geschäftsprozesse autonom auslösen – wie das Unterbrechen einer Marketingkampagne (um die Auslastung zu reduzieren) oder das Vorerstellen einer Kundenbenachrichtigung über die Dienstunterbrechung. Agenten könnten in Disaster-Recovery-Verfahren (Auslösen eines Failovers zu Backup-Rechenzentren) und sogar in das Facility Management bei Ausfällen vor Ort (z. B. Koordinierung eines Neustarts über IoT-Geräte) eingebunden werden.
Im Wesentlichen könnten KI-Agenten als Bindeglied zwischen dem IT-Betrieb und umfassenderen Kontinuitätsplänen dienen und so sicherstellen, dass die Auswirkungen von Vorfällen auf das Geschäft in allen Bereichen gemindert werden. Diese funktionsübergreifende Fähigkeit bedeutet, dass Incident-Management-Agenten mit mehr Systemen (von DevOps-Toolchains bis hin zu CRM und darüber hinaus) zusammenarbeiten, um nicht nur die Infrastruktur, sondern auch das Geschäft zu schützen.
Die sich wandelnde Rolle des Menschen – vom Reagierenden zum Strategen
Da die Automatisierung die unmittelbare „fight-or-flight”-Reaktion übernimmt, wird sich die Rolle des Menschen zunehmend auf die Überwachung und Verbesserung des Prozesses verlagern. Wir können eine Rolle wie die eines KI-Incident-Supervisors oder Automation SRE vorhersehen, dessen Aufgabe es ist, die KI-Agenten zu trainieren, zu optimieren und ihre Leistung zu überprüfen. Der Mensch wird sich mehr auf kreative Problemlösungen, Randfälle und die kontinuierliche Verbesserung der Zuverlässigkeitstechnik konzentrieren. Die Kultur des Incident Managements wird sich in Richtung Ausnahmebehandlung und Systemdesign verlagern – um sicherzustellen, dass die KI über alles verfügt, was sie benötigt, und nur dann einzugreifen, wenn etwas wirklich Neues passiert.
Gleichzeitig wird die tägliche Routinearbeit, wie das Beobachten von Dashboards um 2 Uhr morgens oder das Durchführen von Routinekorrekturen, an Bedeutung verlieren. Dieser Übergang erfordert die Weiterqualifizierung der derzeitigen Mitarbeiter (um sicherzustellen, dass sie die KI-Tools verstehen) und möglicherweise die Einstellung neuer Mitarbeiter (die sowohl über Software-Engineering- als auch über Machine-Learning-Kenntnisse verfügen, um diese Systeme zu warten). Es handelt sich um eine strategische Veränderung: Der SRE der Zukunft wird möglicherweise genauso viel Zeit mit der Kuratierung und Prüfung von KI-Playbooks verbringen wie mit dem Schreiben von Shell-Skripten.
Zusammenfassend lässt sich sagen, dass das agentenbasierte Incident Management in Richtung größerer Intelligenz, Proaktivität und Integration geht. Wir beginnen mit den heute noch relativ begrenzten Co-Piloten und bewegen uns auf eine Zukunft zu, in der KI-Agenten kreativ und kooperativ sind und tief in die IT-Landschaft eingebettet sind. Jeder Schritt erhöht die Anforderungen an Zuverlässigkeit und Geschwindigkeit, erfordert aber auch ein sorgfältiges Management von Komplexität und Risiken.
Unternehmen, die sich diese Zukunft zu eigen machen, werden sich einen Wettbewerbsvorteil in Bezug auf Uptime und operativer Flexibilität verschaffen, vorausgesetzt, sie bringen Fortschritt mit Ethik, Sicherheit und menschlichen Belangen in Einklang.
Die folgenden Anhänge enthalten einige konkrete Vorlagen und Checklisten, die in der aktuellen Phase dieser Entwicklung hilfreich sind – von der Deduplizierung von Warnmeldungen bis zur Strukturierung von Nachbesprechungen – und die Lücke zwischen traditionellen Praktiken und der agentenbasierten Zukunft schließen.







